[ML] Pytorch tutorial and Regression
时隔两年重新开始写博客,毕设基本结束,现在先开始跟着李宏毅的课程,系统学习一下。
Pytorch Tutorial
数据读入
dataset和dataloder,dataset读入(stores data samles),dataloder使用(groups data in batches)
from torch.utils.data import Dataset,DataLoader
dataset = MyDataset(file)
dataloder = DataLoader(dataset,batch_size,shuffle=True)
#train的时候开shuffle,test的时候关dataloader每次按序(shuffle=false的情况)从dataset中取出batch_size个变成一个batch。
关于为什么要shuffle的说明数据集shuffle的重要性 - 知乎 (zhihu.com)
定义dataset
# 定义MyDatasetfrom torch.utils.data import Dataset,Dataloader
class MyDataset(Dataset):
#初始化,对data处理
def __init__(self,file):
self.data = =....
#返回单个
def __getitem__(self,index):
return self.data[index]
#获取dataset长度
def __len__(self):
return len(self.data)Tensors
Tensor是高维度的矩阵,是信息读入后存在Pytorch中的形式。
dim in Pytorch == axis in NumPy\
一些常用操作
# 用shape看大小
x.shape()
# list to tensor
x = torch.tensor([1,0],[0,1])
# numpy to tensor
x = torch.from_numpy(np.array([1,0],[0,1]))
# zeros和ones
x = torch.zeros([2,2,2])# generate a 2*2*2 3dim tensor filled with 0
# rand
x = torch.rand([2,2,2]) # generate a 2*2*2 random 3dim tensor
# 常见运算+-,sum(),mean(),pow()
y = x.pow(2)
# transpose,指定两个dimension互换,如2*3变3*2
y = x.transpose(0,1) # change dim0 and dim1
# squeeze,拿掉长度为1的dimention,如
x = torch.zeros([1,2,3]) #generate a 1*2*3 tensor
x = x.squeeze(0) #squeeze to an 2*3 tensor
x = x.unsqueeze(1) # unsqueeze to an 2*1*3 tensor
# cat,把多个tensor连接在一起
x = torch.zeros([2,1,3])
y = torch.zeros([2,3,3])
z = torch.zeros([2,2,3])
w = torch.cat([x,y,z],dim = 1)
# 沿dim1方向连接
# torch size [2,6,3]Tensor - Datatype
# 32bit float
torch.float
torch.FloatTensor
# 64bit integer
torch.long
torch.LongTensor
#use dtype to check the datatype
x.dtypeTensor - Device
Tensor will be computed with CPU by default.
use to() to move tensor to appropriate device like:
x = x.to('cpu')
# to gpu
x = x.to('cuda')
# multi gpu
x = x.to('cuda:0') #cuda:1,cuda:2.....Tensor - Gradient
使用pytorch提供的函数求梯度
z.backward求z微分,用x.grad看结果

训练前
进入训练之前三件事情,定好layers,损失函数loss function,optimization algorithm最佳化演算法
Linear Layer(fully connected layer)
linear layer包含一组bias和一组weight
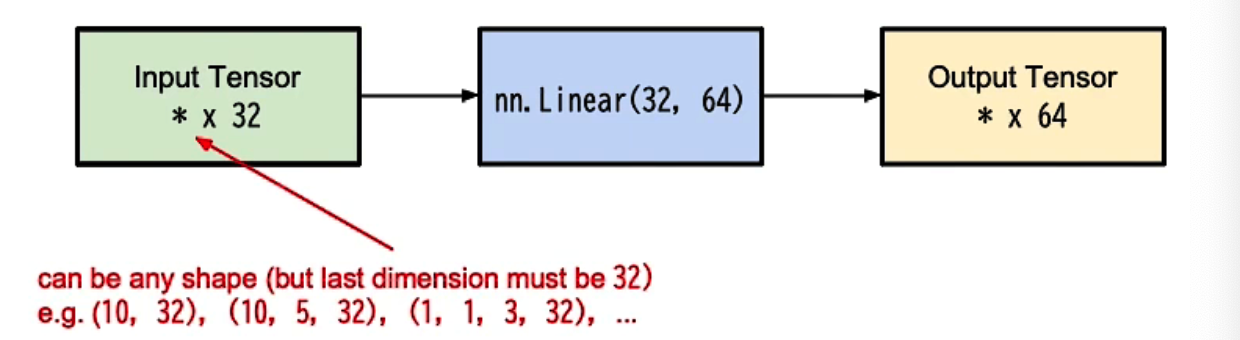
如图即让(?,32)大小的输入x乘上(32,64)的W,再加上b。先做一次矩阵乘法再做一次加法。$y = W\cdot x+b$
layer = torch.nn.Linear(32,64)
layer.weight.shape
layer.bias.shape
# 可以用weight和bias.shape看linear层中w和b参数的大小
# 参数
nn.Linear(in_feature,out_feature,bias)两种定义网络结构的方法
关于super(Mymodel,self).__init__()这句简言之就是对继承自父类nn.Module的属性进行初始化。super()是用来用于调用父类的一个方法。这里参考了(解惑(一) —– super(XXX, self).init()到底是代表什么含义_self.fc3是_底层研究生的博客-CSDN博客
import torch.nn as nn
# 再自己定义网络时,需要继承nn.Module类,并且重新实现构造函数Init和forwawrd两个方法
class MyModel(nn.Module):
# 第一种方法,使用序列容器Sequential
def __init__(self):
super(Mymodel,self).__init__()
self.net = nn.Sequential( # sequential是pytorch的一个序列容器
nn.Linear(10,32),
nn.Sigmoid(),
nn.Linear(32,1)
)
def forward(self,x): # 前向传播
return self.net(x)
class MyModel(nn.Module):
# 第二种方法,再forward中相继调用
def __init__(self):
super(Mymodel,self).__init__()
self.layer1 = nn.Linear(10,32)
self.layer2 = nn.Sigmoid()
self.layer3 = nn.Linear(32,1)
def forward(self,x): # 前向传播
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
return outtorch.optim
最佳化演算法即选择调整model参数的方法,比如SGD演算法,在torch.optim这个library中。
torch.optim.SGD(model.parameters(),lr,momentum = 0)再定好最佳化演算法后,在每个batch都需要有这三步。
optimizer.zero_grad() # 把上一步的gradient归零
loss.backward() # 计算loss的gradient
optimizer.step() # 利用gradient调整model的参数完整训练过程
关于Training,validation,testing的区别训练集(train)验证集(validation)测试集(test)与交叉验证法 - 知乎 (zhihu.com)
Training Loop训练
dataset = Mydataset(file) #read data
tr_set = DataLoader(dataset,16,shuffle=True) # put dataset into dataloader
model = MyModel().to(device) # device 可以是 cpu/cuda
criterion = nn.MSELoss() #选择损失函数
optimizer = torch.optim.SGD(model.parameters(),lr,momentum = 0) #选择optimizer
for epoch in range(n_epoch):
model.train() # 这句是把model设置成training mode
for x,y in tr_set:
optimizer.zerograd() # 1.把上一步的gradient归零
x,y = x.to(device) , y.to(device) #放到设备上去
pred = model(x)
loss = criterion(pred,y) # 预测值和期望结果计算loss
loss.backward() # 2.计算loss的gradient
optimizer.step() # 3.利用gradient调整model的参数Validation Loop验证
用于在训练过程中检验模型的状态,收敛情况
model.eval() # 这句是把model设置成evalidation mode
total_loss = 0
for x,y in dv_set:
x,y = x.to(device),y.to(device)
with torch.no_grad(): #关闭梯度
pred = model(x)
loss = criterion(pred,y)
total_loss += loss.cpu().item() * len(x) # 收集loss
avg_loss = total_loss / len(dv_set.dataset) # 计算平均lossTesting Loop测试
model.eval()
preds = []
for x in tt_set:
x = x.to(device)
with torch.no_grad(): #和evalidation一样关闭梯度
pred = model(x)
preds.append(pred.cpu()) # 把预测值pred手机到preds中去model的一些layers在testing和training的时候的行为时不一样的,比如dropout,所以需要开evalidation mode。
在testing和validation的时候我们比希望model学习到这些资料,所以这时候用torch.no_grad把梯度关掉。
save/load models
# save model
torch.save(model.state_dict() , path)
# load model
ckpt = torch.load(path)
model.load_state_dict(ckpt)官方文档
PyTorch documentation — PyTorch 2.0 documentation
常用套件
torch.nn -> neural network
torch.optim -> optimize function
Torch.utils.data -> dataset,dataloader
一些常见error
Tensor on Different Device to model
model和input要放到一个设备上
# 正确写法
model = torch.nn.Linear(5,1).to("cuda:0")
x = torch.rand(5).to("cuda:0")Mismatched Dimensions
不同大小的矩阵相加,用transpose使大小相同
x = torch.randn(4,5)
y = torch.randn(5,4)
# transpose
y = y.transpose(0,1) # transpose dim1 and dim0
z = x + yCuda Out of Memory
batch size of data is too larch to fit in GPU,应当减少batch size。
如果batch已经减少到1了,则可能是model太大,考虑减少model大小。
Mismatched Tensor Type
需要转换tensor的类型,如换成long,用label = label.long()
Regression
老师课上的举例,回归问题就是找function,如最简单的可能就是$y = w\cdot x+b$,其中w为weight,b为bias。
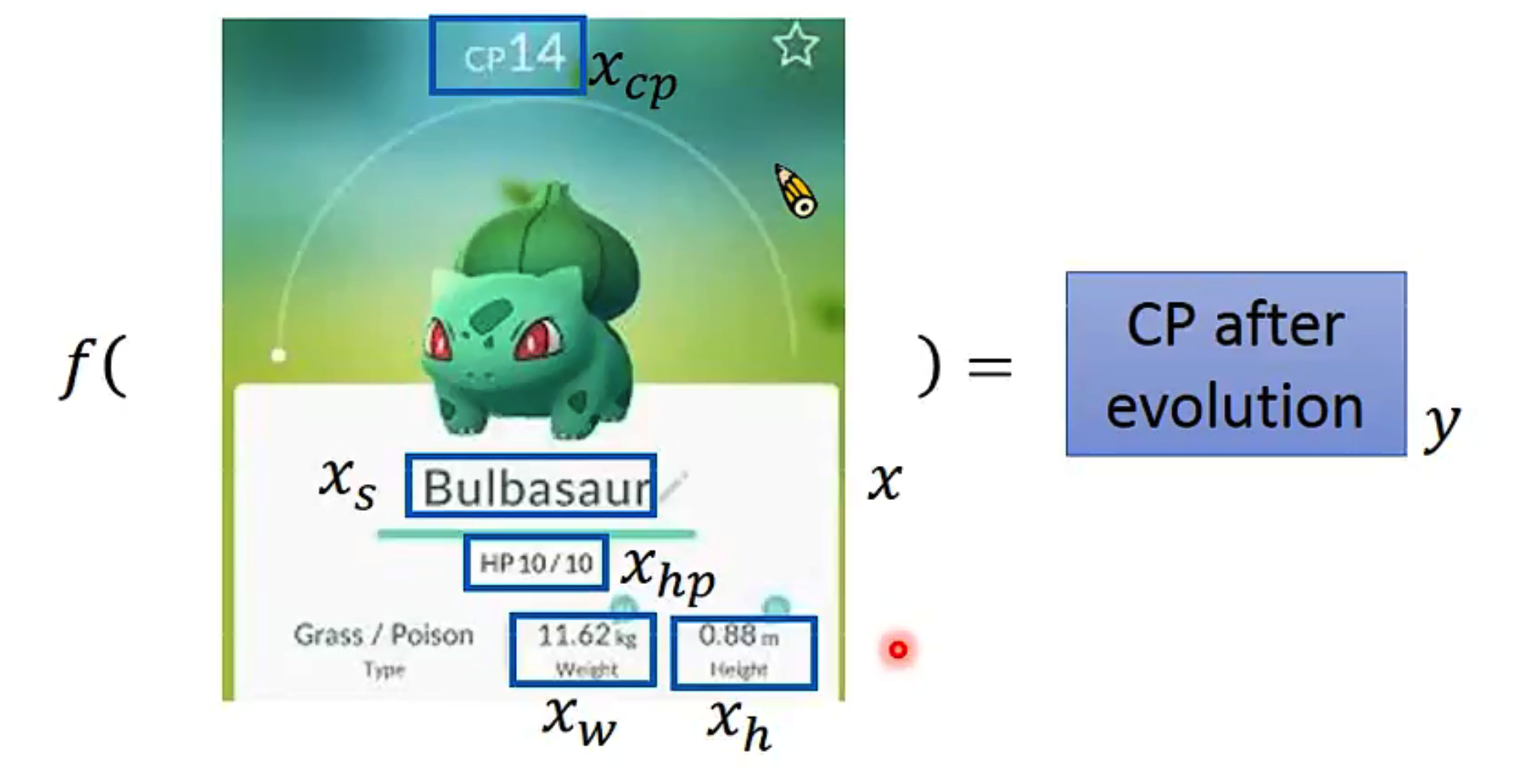
Liear model线性模型$y=b+\sum w_ix_i$
Loss function
Input:a function
Output:how bad it is
衡量一组参数的好坏$L(f) = L(w,b)$
使用估计值-实际值取平方相加并求和,即$L(w,b) = \sum_{n=1}^{10}(\hat{y}^n-(w\cdot x^n+b))^2$
找loss最小的function,写作$f^* = arg \min_fL(f)$
$w^*,b^* = arg\min_{w,b}L(w,b)$
使用gradient descent梯度下降来找这个f
Gradient Descent
移动参数 $-\eta \frac{dL}{dw}|_{w=w_0}$,其中$\eta$是learning rate
如果有两个参数w,b的情况,一样是计算$\frac{\partial L}{\partial w}|{w=w^0}$和$\frac{\partial L}{\partial b}|{b = b^0}$两个偏微分
在二维上理解,梯度方向就是等高线的方向。
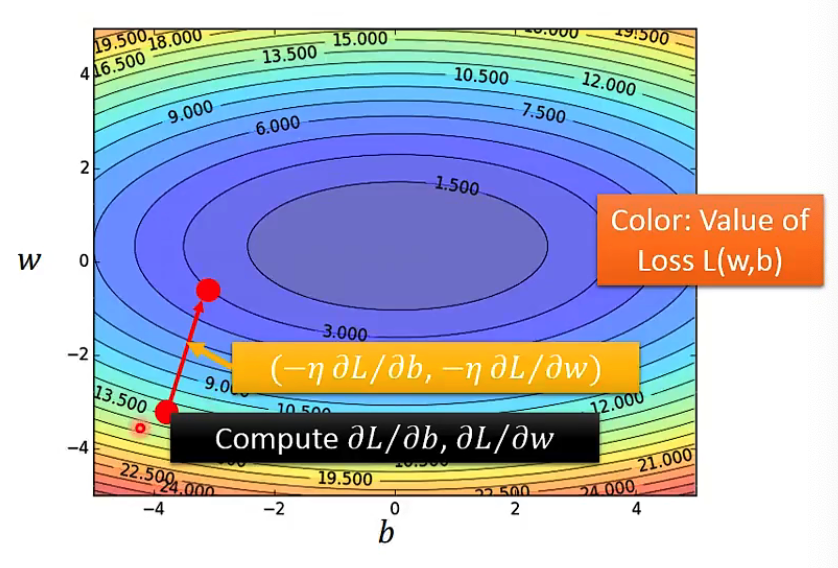
在Linear regression问题中不存在local optimal,所以不需要考虑找到的只是局部最优。
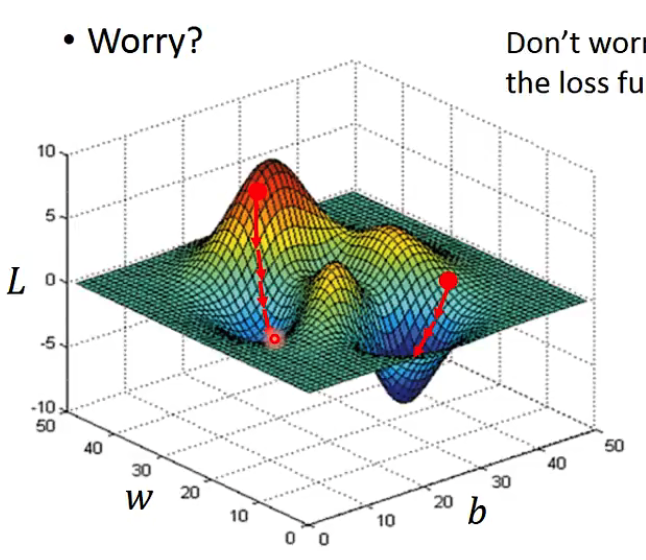
In Linear Regression the loss function L is convex,故不用担心沿着gradient方向找到的只是局部最优解的情况了。即在Linear Regression问题中,Loss function关于w和b的图如上面的图,是形如一个椭圆形的。
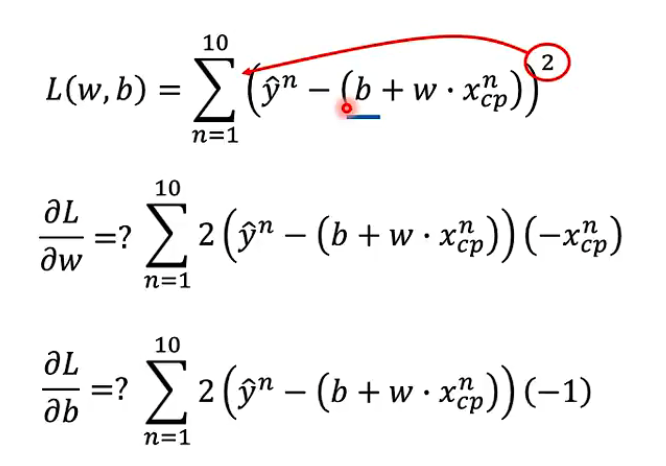
用求偏导的方式计算Lossfunction对w和b的偏微分,过程如上。
有时候这种wx+b的模型太简单,可以尝试引入二次项,如$y=b+w_1\cdot x+w_2\cdot x^2$
效果比单纯一次的模型要更好,同理,可以再增加三次项、四次项$y=b+w_1\cdot x+w_2\cdot x^2 + w_3\cdot x^3$
over fitting
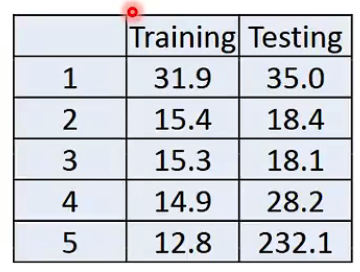
老师在把模型增加到五次的时候,在trainning data的表现有继续变优,但是testing data反而效果变差了
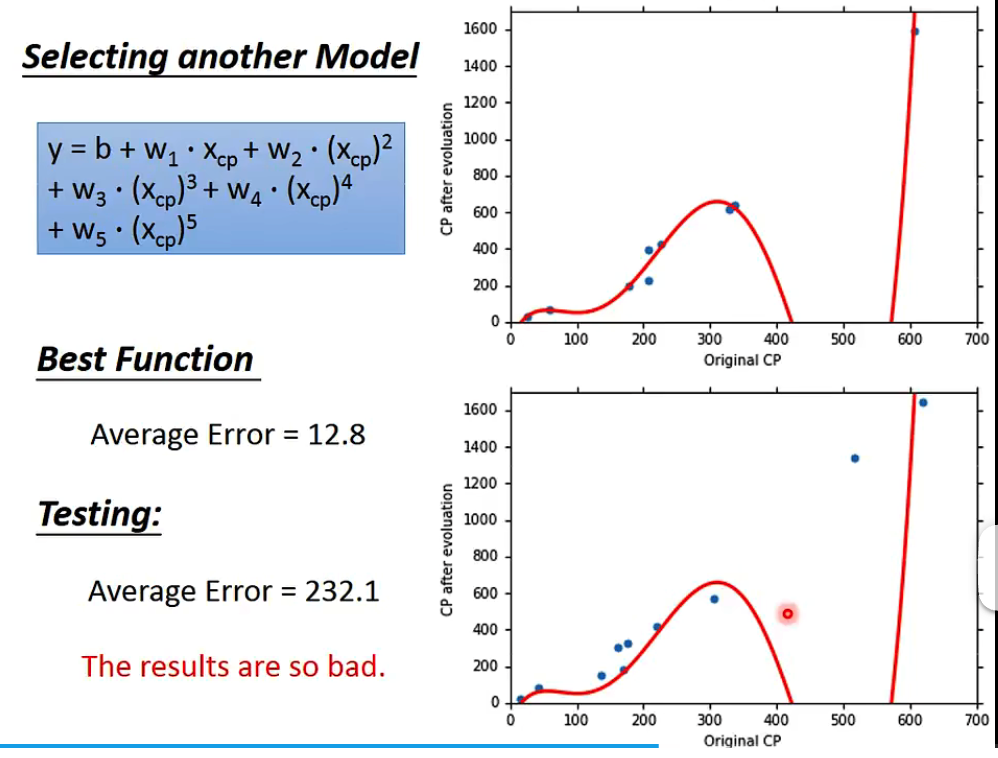
A more complex model does not always lead to better performance on testing data!This is called OverFitting.
所以选择合适的model是一件重要的事情,比如图中的情况显然应当选择3次的model。
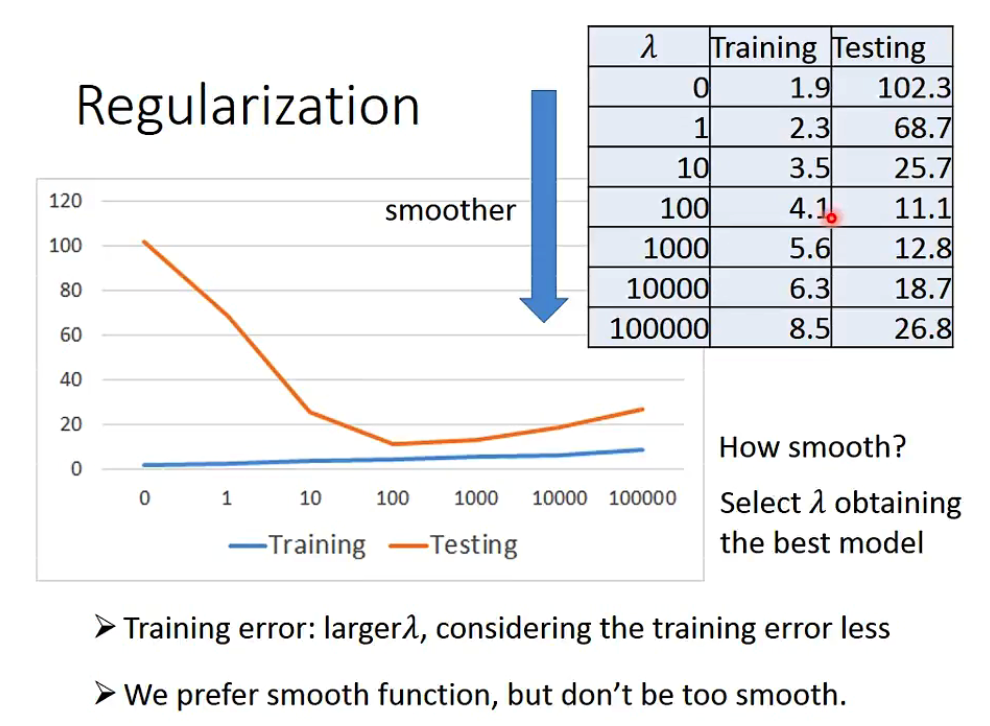
regularization
在现有Features不变情况下,降低部分不重要Features的影响力。这个方法有助于有很多Features且每个Features都有贡献的Neural Network避免Overfitting。

老师的话是,regularization将w平方乘以$\lambda$加入损失函数,有利于让function更加平滑,在实际实验中,regularization能有效的避免overfitting,在训练集中的loss可能会变差,但是在testing中的效果会提升。
Colab tutorial
Google Colab Tutorial 2023 - Colaboratory
Google Colab 快速上手 - 知乎 (zhihu.com)
很重要!colab防断线
(160条消息) colab防止掉线断连及清除方法_colab断开连接_jinniulema的博客-CSDN博客
function ConnectButton(){
console.log("Connect pushed");
document.querySelector("#top-toolbar > colab-connect-button").shadowRoot.querySelector("#connect").click()
}
setInterval(ConnectButton,60000);
# 结束
clearInterval(intervalId) # intervalId换成具体的数字作业1 : 新冠预测Regression
给定1,2,3天的资料,每天的资料是survey和positive cases
input
- 输入包括一个35维度的one-hot vector表示州,后面还跟着一系列feature,其中第三天的test positive case是我们需要预测的


- one-hot vector就是一个向量里面只有一个元素为1,其余全是0。在作业中,所在州的编码就是一个onehot vector。
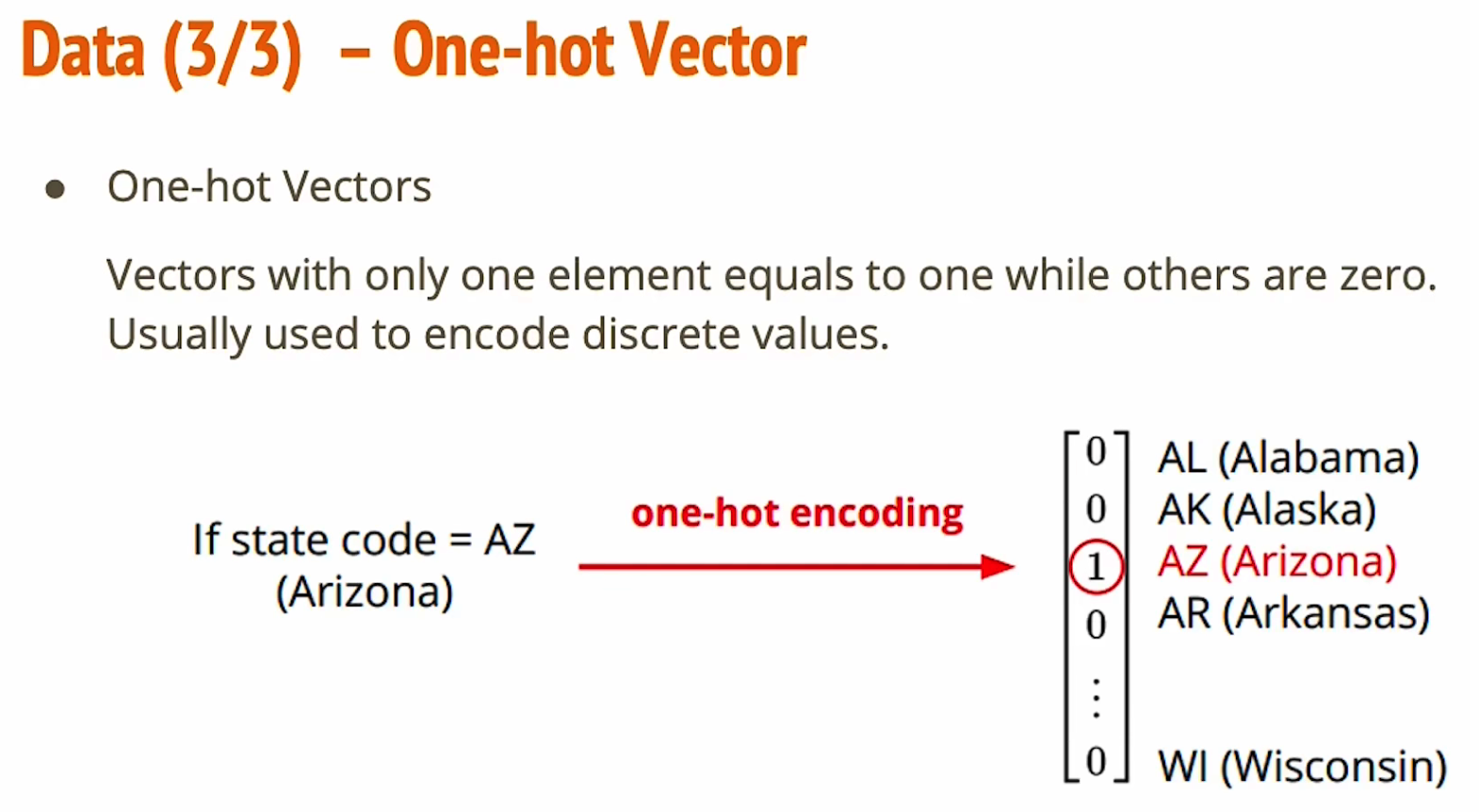 使用MSE(mean squared error)均方误差
使用MSE(mean squared error)均方误差
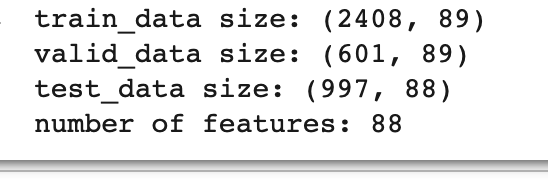
关于feature的大小,打印如下,88个特征我认为是35个州,加上三天的特征(5+5+2+2+3+1)*3 = 54 ,因为最后一天的那个1,感染人数是要预测的,所以-1,即35+54-1 = 88个特征值,一个预测值。
sample code复现
固定seed
def same_seed(seed):
'''Fixes random number generator seeds for reproducibility.'''
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)为了固定训练用的seed,让训练结果能够复现,一共四种随机种子,都输入预设好的seed值,在config中可以设置
train 和 valid data的划分
def train_valid_split(data_set, valid_ratio, seed):
'''Split provided training data into training set and validation set'''
valid_set_size = int(valid_ratio * len(data_set))
train_set_size = len(data_set) - valid_set_size
train_set, valid_set = random_split(data_set, [train_set_size, valid_set_size], generator=torch.Generator().manual_seed(seed))
return np.array(train_set), np.array(valid_set)valid_ratio在config中可以设置的一个比例。
random_split把seed输进去
predict预测
def predict(test_loader, model, device):
model.eval() # Set your model to evaluation mode.
preds = []
for x in tqdm(test_loader):
x = x.to(device)
with torch.no_grad():
pred = model(x)
preds.append(pred.detach().cpu())
preds = torch.cat(preds, dim=0).numpy()
return preds比较直观,set成evalidation mode,tqdm是一个用于展示迭代进度条的库
在preds用append()函数往后面插入结果。
pred是当前这次预测的结果,这里的pred.detach().cpu()我查阅资料后的理解:
pred是device:cuda得到的cuda tensor,在官方文档对detach()的说明是返回一个不包含gradient梯度的tensor(detach的含义是分离)
Returns a new Tensor, detached from the current graph.
The result will never require gradient.但是pred.detach()是一个gpu类型的tensor,这时候调用cpu(),转化成cpu tensor类型才可以被list读取。
dataset定义
class COVID19Dataset(Dataset):
'''
x: Features.
y: Targets, if none, do prediction.
'''
def __init__(self, x, y=None):
if y is None:
self.y = y
else:
self.y = torch.FloatTensor(y)
self.x = torch.FloatTensor(x)
def __getitem__(self, idx):
if self.y is None:
return self.x[idx]
else:
return self.x[idx], self.y[idx]
def __len__(self):
return len(self.x)包括初始化init,取单个元素getitem,取长度len
定义model
class My_Model(nn.Module):
def __init__(self, input_dim):
super(My_Model, self).__init__()
# TODO: modify model's structure, be aware of dimensions.
self.layers = nn.Sequential(
nn.Linear(input_dim, 16),
nn.ReLU(),
nn.Linear(16, 8),
nn.ReLU(),
nn.Linear(8, 1)
)
def forward(self, x):
x = self.layers(x)
x = x.squeeze(1) # (B, 1) -> (B)
return x这里的super之前讲过是调用父类nn.Module的init函数
然后也有了我们第一个任务,即完成对layers的修改
这里的layers输入第一层就是input_dim,后来想了一下,其实这么设定的原因是因为有select_feat选择特征函数,所以这里的输入vector维度是不确定的。
特征选择
通过select_feat函数减少特征的维度,即设定传入哪些特征
def select_feat(train_data, valid_data, test_data, select_all=True):
'''Selects useful features to perform regression'''
y_train, y_valid = train_data[:,-1], valid_data[:,-1]
raw_x_train, raw_x_valid, raw_x_test = train_data[:,:-1], valid_data[:,:-1], test_data
if select_all:
feat_idx = list(range(raw_x_train.shape[1]))
else:
feat_idx = [0,1,2,3,4] # TODO: Select suitable feature columns.
return raw_x_train[:,feat_idx], raw_x_valid[:,feat_idx], raw_x_test[:,feat_idx], y_train, y_valid这里其实诸如train[:,-1]这样的语法不太理解。
train[:, -1], 是说对train这个二维的数据,逗号分隔开的前面的”:”是说取全部的行,逗号后面的-1是说取最后一列。
如果换成一维数组会容易理解,比如list[:]取全部的列 以及list[-1]取最后一个。
而后面的b = a[i:j]
表示复制a[i]到a[j-1],以生成新的list对象
a = [0,1,2,3,4,5,6,7,8,9]
b = a[1:3] # 得到[1,2]而如果不填,则默认为0,所以代码中的[:,:-1]其实是[:,0:-1]
trainning
torch.optism.SGD参数:第一个是网络的参数,第二个lr是learning rate,第三个momentum是冲量,即$v’ = -dx*lr + v\cdot momentum$即每次的更新量在之前的梯度计算基础上,还要加上上次的更新量乘上一个momentum。
for epoch in range(n_epochs):
model.train() # Set your model to train mode.
loss_record = [] #记录loss
# tqdm is a package to visualize your training progress.
train_pbar = tqdm(train_loader, position=0, leave=True)
for x, y in train_pbar:
optimizer.zero_grad() # Set gradient to zero.
x, y = x.to(device), y.to(device) # Move your data to device.
pred = model(x)
loss = criterion(pred, y)
loss.backward() # Compute gradient(backpropagation).
optimizer.step() # Update parameters.
step += 1
loss_record.append(loss.detach().item())
# Display current epoch number and loss on tqdm progress bar.
train_pbar.set_description(f'Epoch [{epoch+1}/{n_epochs}]')
train_pbar.set_postfix({'loss': loss.detach().item()})
mean_train_loss = sum(loss_record)/len(loss_record)
writer.add_scalar('Loss/train', mean_train_loss, step)每个epoch中分train和validation两个部分
model.eval() # Set your model to evaluation mode.
loss_record = []
for x, y in valid_loader:
x, y = x.to(device), y.to(device)
with torch.no_grad():
pred = model(x)
loss = criterion(pred, y)
loss_record.append(loss.item())
mean_valid_loss = sum(loss_record)/len(loss_record)
print(f'Epoch [{epoch+1}/{n_epochs}]: Train loss: {mean_train_loss:.4f}, Valid loss: {mean_valid_loss:.4f}')
# writer.add_scalar('Loss/valid', mean_valid_loss, step)
if mean_valid_loss < best_loss:
best_loss = mean_valid_loss
torch.save(model.state_dict(), config['save_path']) # Save your best model
# 即如果当前的loss比bestloss更好,才会save model
print('Saving model with loss {:.3f}...'.format(best_loss))
early_stop_count = 0
else:
early_stop_count += 1
if early_stop_count >= config['early_stop']:
print('\nModel is not improving, so we halt the training session.')
return在validation中将mode设置为eval,另外和之前pytorch tutorial中一样,关闭grad,主要目的就是因为validation是不改变参数的。
这里还添加了一个earlystop,即通过config中设置的参数early_stop(默认600),当模型经过600次都没有改进,则停止训练。
dataloader
same_seed(config['seed'])
train_data, test_data = pd.read_csv('./covid_train.csv').values, pd.read_csv('./covid_test.csv').values
train_data, valid_data = train_valid_split(train_data, config['valid_ratio'], config['seed'])
# Print out the data size.
print(f"""train_data size: {train_data.shape}
valid_data size: {valid_data.shape}
test_data size: {test_data.shape}""")
# Select features
x_train, x_valid, x_test, y_train, y_valid = select_feat(train_data, valid_data, test_data, config['select_all'])
#通过select_feat中的
# Print out the number of features.
print(f'number of features: {x_train.shape[1]}')
train_dataset, valid_dataset, test_dataset = COVID19Dataset(x_train, y_train), \
COVID19Dataset(x_valid, y_valid), \
COVID19Dataset(x_test)
# Pytorch data loader loads pytorch dataset into batches.
train_loader = DataLoader(train_dataset, batch_size=config['batch_size'], shuffle=True, pin_memory=True)
valid_loader = DataLoader(valid_dataset, batch_size=config['batch_size'], shuffle=True, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size=config['batch_size'], shuffle=False, pin_memory=True)输出的训练集,valid集和test集的大小如下,由于没做featureselect ,所以还是88维的输入。
train_data size: (2408, 89)
valid_data size: (601, 89)
test_data size: (997, 88)
number of features: 88todolist
- modify model’s structure, be aware of dimensions. 更改layers
- Select suitable feature columns.选择重要的feature
- Define your optimization algorithm.选择optimization
optimization
我做了什么
在colab上保存了sample code的副本,阅读代码
通过google drive导入数据集
运行sample code生成pred.csv,上传到kaggle上,得分(1.68198,185034)
尝试修改layers层,增加了一层
nn.Linear(input_dim, 16),
nn.ReLU(),
nn.Linear(16, 8),
nn.ReLU(),
nn.Linear(8, 4)
nn.ReLU(),
nn.Linear(4, 1)
# add a layer
# 原本是nn.Linear(8, 1)就结束了的最后上传到kaggle的效果反而变差了(3.90553,3.28428)
- 尝试增加instancenorm1d归一化层
nn.Linear(input_dim, 32),
nn.InstanceNorm1d(32),
nn.ReLU(),
nn.Linear(32, 8),
nn.InstanceNorm1d(8),
nn.ReLU(),
nn.Linear(8, 1),
# 最后这里加不加激活函数呢?
# nn.InstanceNorm1d(1),
# nn.ReLU(),使用归一化后效果还不如最开始什么都不加的。。
思考了一下会不会是因为之前增加层数导致需要更多的epoch,所以尝试一下增加层数并且增加归一化层。
代码复现
torch.optism.SGD参数:第一个是网络的参数,第二个lr是learning rate,第三个momentum是冲量,即$v’ = -dx*lr + v\cdot momentum$即每次的更新量在之前的梯度计算基础上,还要加上上次的更新量乘上一个momentum。



