[ML] Classification
参考了hexo+typora 插入图片的简便解决方案 - lzlz000的方法,在markdown的开头添加了
typora-root-url: ../可以解决在本地编辑是无法预览图片的问题。
为什么不能用regression的方法解决分类问题
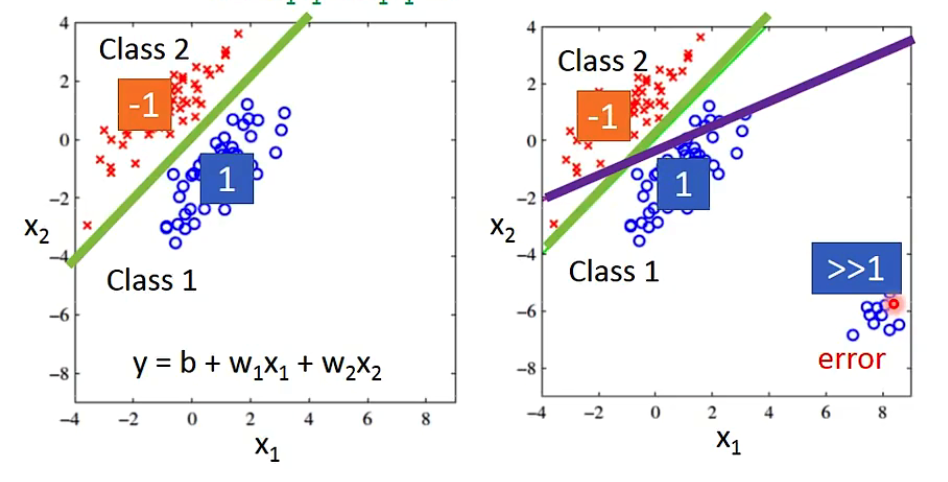
如图,使用regression方法时,接近1记为class1,接近-1记为class2,这种情况下计算损失函数时,如果出现图2中的情况,则远处的那一块蓝色的会有很大的损失,即会惩罚那些output值太大的点。这时候模型会把原本优秀的绿色线调整为这条蓝色的,因为这条线在计算loss时对regression来说是更好的function(loss更小)。
- 简而言之:regression对model好坏的定义不适合用在classification
而且在多种class的时候,如果说把1当作class1,2当作class2,3当作class3,显然是不可以的,因为这样class1和class2之间,class2和class3这些相邻组之间存在一定关系,但实际情况上可能不存在这样的关系。
应该如何实现
在fxgx嵌套,使用g得出一个值,然后f判断分类

我们知道之前regression中间,优化function的方法是gradient decent,但是显然这个loss函数没法微分,所以这里需要用到如:SVM、Perceptron (老师说之后讲)的优化方法。
G
实现二元分类为例

算x是属于class的概率计算公式如图,要实现概率的计算,需要用trainning data估测出$P(C_1)P(C_2)P(x|C_1)P(x|C_2)$的这四个值。(选C1的概率,选C2的概率,在C1中抽出x的概率,在C2中抽出x的概率。
这样的模型叫做生成模型generative model,即可以自己产生一个x,因为可以计算某个x出现的几率$P(x) = P(x|C_1)\cdot P(C_1) + P(x|C_2)\cdot P(C_2)$即在C1中挑出的几率和C2中挑出的几率。
Prior
$P(C_1)andP(C_2)$这两个概率叫prior。
比如class1有79个,class2有61个,则容易解$P(C_1) = 79/(79+61)$
Probability from Class
计算$P(x|C_1)$即从C1中挑一个样本出来,这个样本正好是x的概率

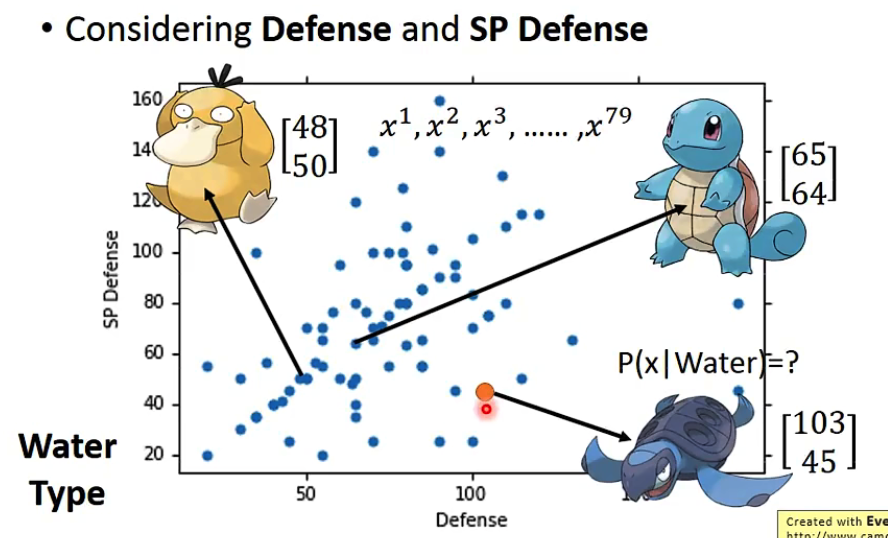
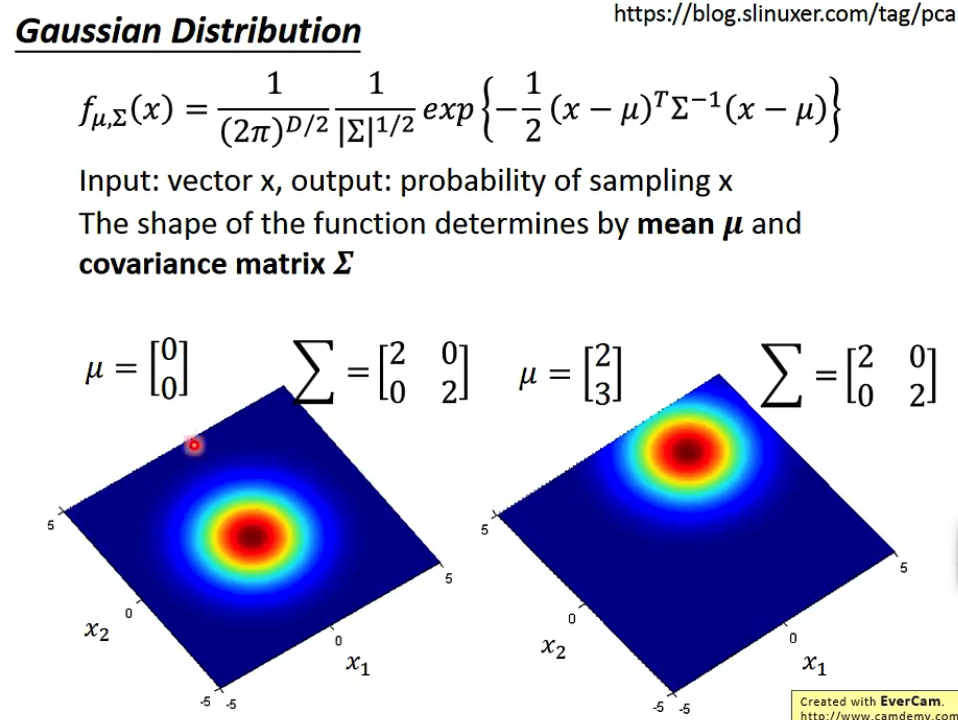
老师举出的例子中海龟是一个不在集合里面的样本,虽然海龟不在水系神奇宝贝的样本中,但是显然海龟属于水系神奇宝贝的概率并不为0,假设水系神奇宝贝的防御和sp服从一个正态分布gaussian distribution,则可以通过这个正态分布计算出海龟属于水系神奇宝贝的概率。
正态分布由两个参数决定,一个是mean$\mu$和一个矩阵convariance matrix$\sum$。