主要任务
文本对话
方案A:问答形式数据对chatglm-6B进行微调
方案B:基于本地知识库
爬虫收集农业知识库
对应方案A需要问答形式的数据,B的话需要文本形式,可以从论文或者网页爬虫中获取。
针对爬取结果设置过滤词,使不要爬到无关词条

8月10日及之前
已完成的
部署langchain+chatglm基于本地知识库问答 到autodl云服务器,并且导入少量农业知识数据进行测试
导入txt文件时报错,查看github issue发现是因为文档中有无法识别的字符,用程序去除
运行开源中文wiki爬虫代码
问题
- 运行开源的中文维基爬虫bug很多
wjn1996/scrapy_for_zh_wiki: 基于scrapy的层次优先队列方法爬取中文维基百科,并自动抽取结构和半结构数据 (github.com)
- scrapy使用代理访问外网
8月11日
尝试继续跑通爬虫代码
云服务器安装了正确版本的库,代码不再报错,但是出现tcp connection timeout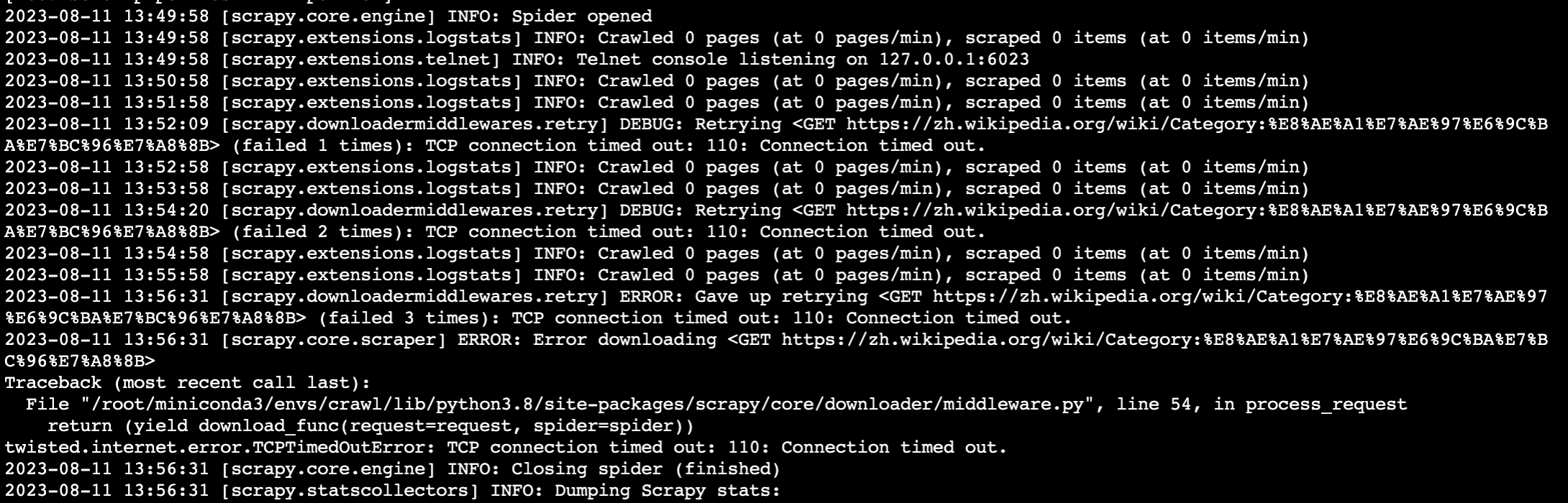
本地端则是能够获取到wiki的category分类页面,但是通过调试发现获取分类页面内容的url似乎有问题,查看list为空。
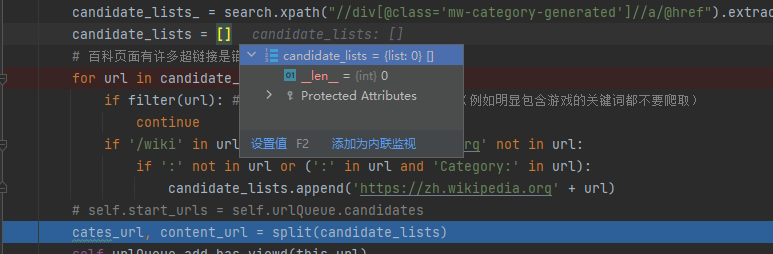
非常奇怪,考虑了一下可能是下面两种原因:
- 怀疑是否是代理的原因?我使用的是clash的tun模式,看到网上一些帖子说要额外写一个scrapy的中间件middleware。
- zh-wiki网页的代码发生变化,需要重新找方法获取分类页面下面的url?
替代方案:对ecnu爬取好的数据进行处理,使得符合我们需要的格式
ecnu爬取的数据格式不同,而且存在很多不相关的词条

编写脚本,实现如下功能
- 取引号内
- 根据设定的列表 filter_words 删去没必要的词条
- 重复爬取的词条进行去重
import re
import sys
sys.path.append(".")
from filter_words import filters
def contains_filtered_word(line, filter_list):
for word in filter_list:
if word in line:
return True
return False
inpt = open("train_data.txt","r",encoding='utf-8')
outpt = open("outpt.txt","w",encoding='utf-8')
# 按行读入
cleaned_lines = []
lines = inpt.readlines()
def baoliu(line):
# 找开头的引号
for i in range(len(line)-1,0,-1): #倒着遍历
if line[i] == '"':
ed = i
break
# 找结尾的引号
for i in range(0,len(line)-1):
if line[i] == '"':
st = i
break
# 取st和ed中的子串
# return line[st:ed+1]
return line[st+1:ed]
# 清洗
cleaned_lines = []
for line in lines:
# match = re.search(r'"([^"]+)"', line) # 会有bug,找最外层的双引号
# match = re.findall(r'"([^"]+)"', line)
match = baoliu(line)
if contains_filtered_word(line,filters): # 接触到屏蔽词 跳过
continue
if match:
if match+'\n' not in cleaned_lines:# 去重
cleaned_lines.append(match+'\n')
outpt.writelines(cleaned_lines)
outpt.close()
inpt.close()清洗后剩余六千多条记录,后续考虑导入知识库中
8月13日
处理问答数据
获得了格式如下的问答数据,编写python程序处理。
给出的问答同样还有不同格式的也通过类似方法进行处理。

import pandas as pd
import re
# 读入
def process_input(input_str):
match = re.match(r"(\d+)\s*、\s*(.*?)\s*答:(.*)", input_str)
if match:
number = match.group(1).strip()
question = match.group(2).strip()
answer = match.group(3).strip()
return {
"img": None,
"prompt": question,
"label": answer,
}
return None
# 开始处理
input_file = "input.txt"
processed_data = []
tmp = ""
with open(input_file, "r", encoding="utf-8") as file:
flag = 0
for line in file:
# 调试用
# print(line[0])
# print(line[0].isdigit)
if line[0]<='9' and line[0]>='0':
if flag:
processed_entry = process_input(tmp)
if processed_entry:
processed_data.append(processed_entry)
tmp = ""
tmp = tmp + line
flag = 1
else:
linep = line.replace('\n', ' ')
tmp = tmp + linep
#结束后还有最后一个
processed_entry = process_input(tmp)
if processed_entry:
processed_data.append(processed_entry)
df = pd.DataFrame(processed_data)
df.to_json("data.json", orient="records",force_ascii=False,indent=4)
print("JSON文件已保存")
#input来源与百度文库将不同问答文件合成后输出到json中去,得到格式如下的json文件
{
"img":null,
"prompt":"玉米实行宽窄行种植有哪些优点?",
"label":"①改善了通风透光条件,发挥边行优势。 ②可以适当增加密度。 ③易于在宽行中间套种矮秆作物,提高经济效益。"
},
{
"img":null,
"prompt":"玉米高产栽培中,为什么提倡抽雄前10天左右追肥浇水?",
"label":"这段时期是玉米雌、雄穗的小穗小花分化期,也是菅养生长和生殖生长并进旺盛期,是玉米一生需肥水最多的关键期。因此,这时追肥浇水可促进穗分化,协调菅养生长和生殖生长,争取穗大、粒多、达、到高产。"
},


