李沐D2L ML部分
colab d2l
- 解决colab没有d2l的问题,使用这个比从github下载更快
!pip install d2l==0.14.注意
避免一些无意义的复制粘贴,只记录一些体会和关键的点。
softmax回归,多层感知机
softmax为了让概率之和为1所引入$ \frac{exp(x_i)}{\sum{exp(x_k)}}$
和sigmoid搞混了,sigmoid是把输入映射到0-1范围的激活函数,softmax是给一组输入,让所有元素之和=1
train函数 这个函数后面的章节也一直通用
# train_iter是一个dataloader
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers())- 之前不理解为什么backward的时候是l.mean.backward(),因为正常用backward的话l得是个标量。还有一种方法是,如果l是向量的话,可以用l.backward(gradient=grad)实现
def train_epoch_ch3(net, train_iter, loss, updater): #@save
"""训练模型一个迭代周期(定义见第3章)"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module): # 这里是看net是不是nn.Module类
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3) # 计数器
for X, y in train_iter: # train iter是
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y) # 计算交叉熵
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad()
l.mean().backward() # 梯度回传
updater.step() # 优化器更新参数
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel()) # 统计loss,准确率用于之后算平均
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save
"""训练模型(定义见第3章)"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc- 可以使用net.apply(f()),来用f对net的参数进行初始化
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);- bias可以用zeros初始化,因为主要作用是对网络输出进行平移
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]- 多层感知机中ReLU的引入,是因为如果不引入激活函数,两个Linear先后加在一起和一个Linear的效果是一样的。(线性模型已经能够表示任何仿射函数)
权重衰减
$L(\mathbf{w}, b) + \frac{\lambda}{2} |\mathbf{w}|^2$
- 计算w的L2范式,这样希望w可以尽量简单
- 关于为什么不开根,因为导数好算很多
- 对大的wi施加更大的惩罚, 使单个特征的误差影响更小
- 避免过拟合
def l2_penalty(w):
return torch.sum(w.pow(2)) / 2
#使用例
# 广播机制使l2_penalty(w)成为一个长度为batch_size的向量
l = loss(net(X), y) + lambd * l2_penalty(w)
l.sum().backward()
d2l.sgd([w, b], lr, batch_size)# 简洁实现
trainer = torch.optim.SGD([
{"params":net[0].weight,'weight_decay': wd},
{"params":net[0].bias}], lr=lr)
# 对w设置权重衰减,b不设Dropout暂退法
- 即使我们有比特征多得多的样本,深度神经网络也有可能过拟合。神经网络过拟合与每一层都依赖于前一层激活值相关,称这种情况为“共适应性”。 作者认为,暂退法会破坏共适应性,就像有性生殖会破坏共适应的基因一样。(好玄学)
- 被关闭的神经元不计算loss
- d2l中的活性值,就是经过Linear和激活函数之后的输出
forward and backward
4.7. 前向传播、反向传播和计算图 — 动手学深度学习 2.0.0 documentation (d2l.ai)
- 里面的图很精炼

- 训练比计算要多用GPU显存,因为要存中间值。torch.require_grad需要自动计算梯度,torch.no_grad一般在验证集,测试集使用,省计算。
数值稳定性和初始化
d2l用了
torch.mm来矩阵相乘,但其实这个落后了,应使用torch.matmul函数支持更广泛的操作。梯度爆炸,对称性,梯度消失概念和原因4.8. 数值稳定性和模型初始化 — 动手学深度学习 2.0.0 documentation (d2l.ai),对称性这个概念还是第一次听,就是两个神经元中间计算的梯度之类的都一样,导致两个直接对称了,可以用dropout打破这种对称。
上面这些问题,之前都一直使用正态分布初始化参数,这章引入了Xvaier初始化
实战kaggle房价预测
处理数据集
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(
train_data.SalePrice.values.reshape(-1, 1), dtype=torch.float32)- 调用df.values取df的value,不然返回的类型是df,报错
ValueError: could not determine the shape of object type 'DataFrame' - 默认是float64,所以加一句
dtype=torch.float32,大多数 GPU 只支持 32 位浮点数计算。
loss
def log_rmse(net, features, labels):
# 为了在取对数时进一步稳定该值,将小于1的值设置为1
clipped_preds = torch.clamp(net(features), 1, float('inf')) # 截断到1以上
rmse = torch.sqrt(loss(torch.log(clipped_preds),
torch.log(labels)))
return rmse.item()- rmse的type是tensor,所以用item返回一个python的浮点数
- 我的疑问是,进行了这种截断后,还能计算梯度吗?gpt回答说可以,而且回传计算梯度的时候,y代入的是截断前的y值。
- clamp这个函数的参数
y_clamped = torch.clamp(y, min=1, max=2) # y截断到1,2之间使用torch的dataloader读数据
# 引入dataloader之类的类
from torch.utils import data
def my_load_array(data_arrays,batch_size,is_train = True): # 代替d2l.load_array
dataset = data.TensorDataset(*data_arrays) # 加星号表示将列表解开入参!而不是只传入一个张量
return data.DataLoader(dataset,batch_size,shuffle=is_train)可能是沐神的失误?
for X,y in train_iter:
optimizer.zero_grad() # 梯度清零
# 沐神的代码,不知道为什么这里不用相对误差yhat/y,我改了一下这部分代码,使用之前写好的rmseloss
# y_pred = net(X)
# ls = loss(y_pred,y)
# 修改的部分
ls = log_rmse(net,X,y) # 使用相对误差
ls.backward() # 反向传播
optimizer.step() # 更新参数- 这段不知道为什么不用说好了的开根的loss来计算误差。
- 修改,注意修改后需要改变rmse的返回值,原本是返回item,会报错
AttributeError: 'float' object has no attribute 'backward'- 需要直接返回tensor,才好包含计算梯度所需的,这样以来统计loss的地方再使用item()得数值即可。
def log_rmse(net,features,labels):
pred = net(features)
clamped_pred = torch.clamp(pred,min=1)
rmse = torch.sqrt(loss(torch.log(clamped_pred),torch.log(labels)))
# 整组传到里面去计算mseloss
return rmse- 不过最后效果完全不如沐神原本的,逆天
标程的小问题
d2l中的标程也应做相应修改才能正常执行
报错:all_features经过处理后类型不符合,告知不能转成tensor,float32
答:某些ide独热编码时会将数据处理成boolean类型,需要指定处理类型为数值型,如int。尝试这么处理,pd.get_dummies(all_features, dummy_na=True, dtype=int)
all_features = pd.get_dummies(all_features,dummy_na=True,dtype=int)调参过程
- 先使用沐神原版的网络结构
折1,训练log rmse0.170212, 验证log rmse0.156864
折2,训练log rmse0.162003, 验证log rmse0.188812
折3,训练log rmse0.163810, 验证log rmse0.168171
折4,训练log rmse0.167946, 验证log rmse0.154694
折5,训练log rmse0.163320, 验证log rmse0.182928
5-折验证: 平均训练log rmse: 0.165458, 平均验证log rmse: 0.170293- 然后增加了网络层层数,很明显是过拟合的数据
def get_net():
return nn.Sequential(
nn.Linear(input_size,5),
nn.ReLU(),
nn.Linear(5,output_size)
)折1,训练log rmse0.123148, 验证log rmse0.263349
折2,训练log rmse0.119781, 验证log rmse0.244233
折3,训练log rmse0.120550, 验证log rmse0.208438
折4,训练log rmse0.179972, 验证log rmse0.332736
折5,训练log rmse0.156284, 验证log rmse0.200350
5-折验证: 平均训练log rmse: 0.139947, 平均验证log rmse: 0.249821- 后面查看曲线,感觉这个可能是lr设置的太大了的原因
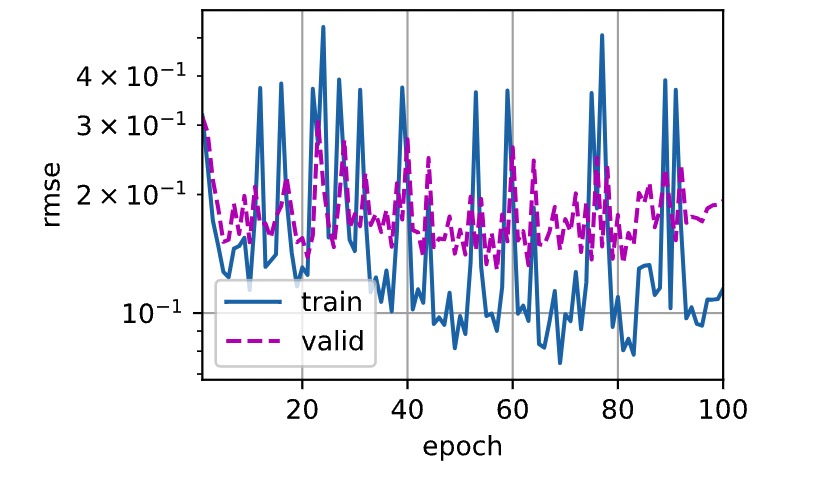
- 考虑减少lr到1
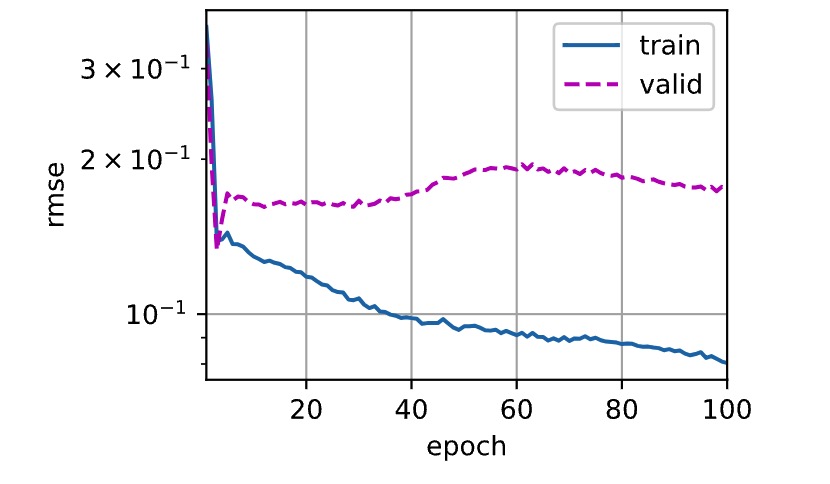
折1,训练log rmse0.080356, 验证log rmse0.175418
折2,训练log rmse0.056644, 验证log rmse0.179348
折3,训练log rmse0.120459, 验证log rmse0.193579
折4,训练log rmse0.101917, 验证log rmse0.149796
折5,训练log rmse0.177175, 验证log rmse0.241251
5-折验证: 平均训练log rmse: 0.107310, 平均验证log rmse: 0.187878- 很明显的overfitting,增加一个dropout
def get_net():
return nn.Sequential(
nn.Linear(input_size,64),
nn.ReLU(),
nn.dropout(p=0.2)
nn.Linear(64,output_size)
)- 发现效果还是不理想,可能因为我增加了dropout,但是却没有设置在valid的时候关dropout,修改代码如下:原来valid的效果差并不是我还overfitting,只是我忘了关dropout
for epoch in range(num_epochs):
net.train()# 开dropout
for X,y in train_iter:
optimizer.zero_grad() # 梯度清零
# 沐神的代码,不知道为什么这里不用相对误差yhat/y,我改了一下这部分代码,使用之前写好的rmseloss
y_pred = net(X)
ls = loss(y_pred,y)
# 修改的部分
# ls = log_rmse(net,X,y) # 使用相对误差
ls.backward() # 反向传播
optimizer.step() # 更新参数
# 记录一下loss
net.eval()
train_ls.append(log_rmse(net,train_features,train_labels).item()) # 因为前面修改了函数,所以这里多加一个item
if test_labels is not None:
net.eval()# 关dropout
test_ls.append(log_rmse(net,test_features,test_labels).item())
return train_ls,test_ls- 对比一下先后的曲线吧,发现确实是这个原因造成的,在valid上面跑的从0.18到0.15的区别。
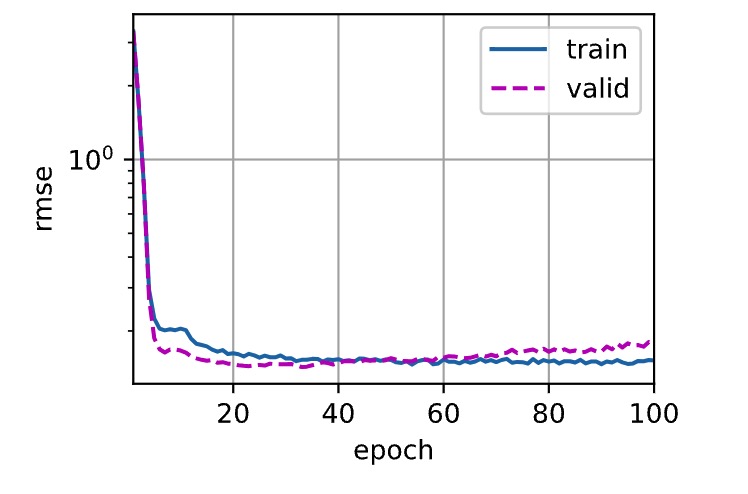
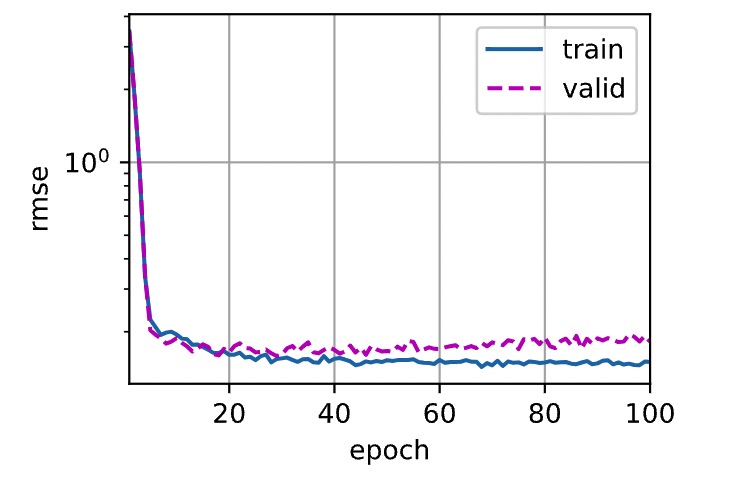
- 后面想想还是不要费时间在调参了
上传kaggle
# 将网络应用于测试集。
preds = net(test_features).detach().numpy()- 这一部分的detach作用和item类似,只不过detach应用于向量,item应用于标量

总结
- 感觉python还是需要再学一下
- 关于如何解决过拟合,使用了ReLU+Dropout的多层感知机也还是不太行
- 不过至少知道了如果loss后面不稳定的话,可以适当调低lr就是了



