我的NLP学习路径
基础
- 本科all in ACM遗憾打铜,现在有点后悔。导致研一入学时基本零基础,跟着李沐d2l学到第五章后开始学习NLP。
一些网址记录
- LLM综述人工智能 LLM 革命破晓:一文读懂当下超大语言模型发展现状 /麦克船长LLM革命系列2 - 知乎 (zhihu.com)
- 李沐的D2L《动手学深度学习》 — 动手学深度学习 2.0.0 documentation (d2l.ai)
给自己的话
2023.11.1
- 刚完成情感分类的任务,感觉自己的代码能力有点差,主要是写的太少了,还是要多结合一下kaggle竞赛之类的练习,coding这块不能落下
word2vec
这篇公式全深入浅出Word2Vec原理解析 - 知乎 (zhihu.com)
skip-gram模型
好理解理解 Word2Vec 之 Skip-Gram 模型 - 知乎 (zhihu.com)
概念:window_size,skip_size
第一个线性层对应词向量,因为输入是one hot,所以和linear相乘即取对应行的词向量!因此这个hidden layer的权重被叫做”查找表“(lookup table)。
因为onehot是稀疏的,实际上不用onehot和矩阵相乘,只需要找到lookup table中对应的行,以节省相乘的计算资源。pytorch提供了
torch.nn.Embedding。训练skipgram是个fake task,实际目的是在训练过程中得到这些词向量
negative sampling方法,为什么能减少计算:
先后的两个loss,其中yij代表ij是否成对。原本是对所有词都计算损失,现在是只用对抽取的正样本和负样本计算loss。
$$
\text{loss} = -\sum_{j=1}^V \left( y_{ij} \log(\sigma(v_i^\top u_j)) + (1 - y_{ij}) \log(1 - \sigma(v_i^\top u_j)) \right)
\
\text{loss} = -\left( \log(\sigma(v_i^\top u_j)) + \sum_{k=1}^{K} \log(\sigma(-v_i^\top u_k)) \right)
$$
CBOW
- 后面还是看沐神的了,14.1. 词嵌入(word2vec) — 动手学深度学习 2.0.0 documentation (d2l.ai)后面CBOW的功能和SkipGram类似,不过是反过来,给上下文求中心词。给定一个大小为左右2m的窗口,利用softmax函数计算中心词的概率。
$$
P(w_c \mid w_{o_1}, \ldots, w_{o_{2m}}) = \frac{\text{exp}\left(\frac{1}{2m}\mathbf{u}c^\top (\mathbf{v}{o_1} + \ldots, + \mathbf{v}{o{2m}}) \right)}{ \sum_{i \in \mathcal{V}} \text{exp}\left(\frac{1}{2m}\mathbf{u}i^\top (\mathbf{v}{o_1} + \ldots, + \mathbf{v}{o{2m}}) \right)}.
$$
- 关于这里的u和v,即对中心词和上下文是两个不同的embedding矩阵进行处理,在训练完成后,取中心词的矩阵作为词向量表。
课后问题
- 让我们以跳元模型为例来思考word2vec设计。跳元模型中两个词向量的点积与余弦相似度之间有什么关系?对于语义相似的一对词,为什么它们的词向量(由跳元模型训练)的余弦相似度可能很高?
因为语义相近的一对词,在训练时上下文对应的词元也比较相似。所以会被训练成比较相近的向量
因为考虑之前计算P的公式是向量点积
如果两个词相近,他们在词向量上:
(1)cosine similarity 接近1
(2)点积较大近似训练
14.2. 近似训练 — 动手学深度学习 2.0.0 documentation (d2l.ai)
- 在计算loss的时候softmax需要遍历整个词表,所以词数量大的时候费用高。故引入近似训练
- 因为使用了sigmoid,为了使其接近1,$\frac{1}{1+e^{-x}}$是x趋近于无穷才好,这样词向量会变得很大,引入随机的噪声(负采样)
$$
P(w^{(t+j)} \mid w^{(t)}) =P(D=1\mid w^{(t)}, w^{(t+j)})\prod_{k=1,\ w_k \sim P(w)}^K P(D=0\mid w^{(t)}, w_k).
$$
- 这样loss计算线性的复杂度依赖于k,而不是整个词表
$$
\text{Loss}(w_i) = -\log(\sigma(\mathbf{v}c \cdot \mathbf{v}{w_i})) - \sum_{j=1}^{k} \log(\sigma(-\mathbf{v}c \cdot \mathbf{v}{n_j}))
$$
word2vec数据集构建
14.3. 用于预训练词嵌入的数据集 — 动手学深度学习 2.0.0 documentation (d2l.ai)
- 高频词下采样(高频词概率删除)
- 负采样和下采样要区分一下概念
- 根据word2vec论文中的建议,将噪声词w的采样概率P(w)设置为其在字典中的相对频率
sampling_weights = [counter[vocab.to_tokens(i)]**0.75
for i in range(1, len(vocab))]代码里面很多实现细节,比如这个draw出来的词要确认一下不在上下文中,才能作为负采样。draw也会抽取重复的元素,不用进行去重。
还有这段随机生成的代码,之前不懂为什么这么写,其实这里是个小优化,一次批量的随机生成和context长度相同的随机词,之后调用draw每次返回一个,目的是省资源。
class RandomGenerator:
"""根据n个采样权重在{1,...,n}中随机抽取"""
def __init__(self, sampling_weights):
# Exclude
self.population = list(range(1, len(sampling_weights) + 1))
self.sampling_weights = sampling_weights
self.candidates = []
self.i = 0
def draw(self):
if self.i == len(self.candidates):# 这里比较精髓,批量生成,单次返回一个
# 缓存k个随机采样结果
self.candidates = random.choices(
self.population, self.sampling_weights, k=10000)
self.i = 0
self.i += 1
return self.candidates[self.i - 1]
def get_negatives(all_contexts, vocab, counter, K):
"""返回负采样中的噪声词"""
# 索引为1、2、...(索引0是词表中排除的未知标记)
sampling_weights = [counter[vocab.to_tokens(i)]**0.75
for i in range(1, len(vocab))]
all_negatives, generator = [], RandomGenerator(sampling_weights)
for contexts in all_contexts:# 遍历每组中心词和context
negatives = []
while len(negatives) < len(contexts) * K: # 这里看出这个K参数是生成k倍于context的负采样
neg = generator.draw()
# 噪声词不能是上下文词
if neg not in contexts:
negatives.append(neg)
all_negatives.append(negatives)
return all_negatives
all_negatives = get_negatives(all_contexts, vocab, counter, 5)- 这里这个batchify感觉也挺巧妙,把之前分开来的center,context和negative整合到一个batch中。它计算所有context和negative的最大长度,然后为了保证batch的长度统一,后面的都用0填充
def batchify(data):
"""返回带有负采样的跳元模型的小批量样本"""
max_len = max(len(c) + len(n) for _, c, n in data)
centers, contexts_negatives, masks, labels = [], [], [], []
for center, context, negative in data:
cur_len = len(context) + len(negative)
centers += [center]
contexts_negatives += \
[context + negative + [0] * (max_len - cur_len)] # 填充0
masks += [[1] * cur_len + [0] * (max_len - cur_len)] # mask,无效的0填充的mask=0
labels += [[1] * len(context) + [0] * (max_len - len(context))] # 正样本1负样本0
# centers展平?
return (torch.tensor(centers).reshape((-1, 1)), torch.tensor(
contexts_negatives), torch.tensor(masks), torch.tensor(labels))- 关于这个reshape,
-1的意思是根据张量的大小自动推断该维度的大小,而1表示该维度的大小为 1。这里的作用和tensor.flatten()是一样的。(多维向量展平)
实现word2vec训练
14.4. 预训练word2vec — 动手学深度学习 2.0.0 documentation (d2l.ai)
- 之前在处理数据集的时候为了batch大小的一致性,引入mask,这在后面的bceloss有体现,即作为nn.functional.binary_cross_entropy_with_logits的参数传入
class SigmoidBCELoss(nn.Module):
# 带掩码的二元交叉熵损失
def __init__(self):
super().__init__()
def forward(self, inputs, target, mask=None):
out = nn.functional.binary_cross_entropy_with_logits(
inputs, target, weight=mask, reduction="none")# 调用
return out.mean(dim=1)
loss = SigmoidBCELoss()- 使用bceloss是因为配合负采样的方法。sigmoidbceloss就是将yhat进行sigmoid后再和y计算bceloss
- 我有点不懂这两个embedding层为什么能加到一个sequential里面去,不是变成顺序执行了吗?
net = nn.Sequential(nn.Embedding(num_embeddings=len(vocab),
embedding_dim=embed_size),
nn.Embedding(num_embeddings=len(vocab),
embedding_dim=embed_size))- gpt说其实不是,是可以这么用的,这样放在里面并不一定是串行
- 然后应用这组embeddinglayer的参数,d2l举例的是通过余弦相似度查找最接近的词
def get_similar_tokens(query_token, k, embed):
W = embed.weight.data
x = W[vocab[query_token]]
# 计算余弦相似性。增加1e-9以获得数值稳定性
cos = torch.mv(W, x) / torch.sqrt(torch.sum(W * W, dim=1) *
torch.sum(x * x) + 1e-9)
topk = torch.topk(cos, k=k+1)[1].cpu().numpy().astype('int32')
for i in topk[1:]: # 删除输入词
print(f'cosine sim={float(cos[i]):.3f}: {vocab.to_tokens(i)}')
get_similar_tokens('chip', 3, net[0])- 这里出现了两个新的函数,一个是torch.mv,实现了类似于matmul的功能,matmul是矩阵x矩阵,mv只能应用于矩阵x向量,mv针对于这种情况专门优化了
- 还有topk:topk(k, dim=None, largest=True, sorted=True) 这里输入参数k=3,使用k=k+1是因为第一名肯定是这个词本身吧
LSTM
9.2. 长短期记忆网络(LSTM) — 动手学深度学习 2.0.0 documentation (d2l.ai)
[干货]深入浅出LSTM及其Python代码实现 (zhihu.com)
- 在循环神经网络RNN中就引入了隐状态的概念,在RNN中是通过隐状态传递之前的信息
$$
\mathbf{H}t = \phi(\mathbf{X}t \mathbf{W}{xh} + \mathbf{H}{t-1} \mathbf{W}_{hh} + \mathbf{b}_h)\
\mathbf{O}_t = \mathbf{H}t \mathbf{W}{hq} + \mathbf{b}_q.
$$
- 在LSTM中,隐状态H和记忆细胞C有什么区别?GPT:H通常用于短期信息的编码,而C则用于长期信息的编码
- 门单元计算如下,有h个隐藏单元和d的输入大小。这里面X的大小是$d\cdot h$,W的大小$h\cdot h$
$$
\begin{split}\begin{aligned}
\mathbf{I}t &= \sigma(\mathbf{X}t \mathbf{W}{xi} + \mathbf{H}{t-1} \mathbf{W}_{hi} + \mathbf{b}i),\
\mathbf{F}t &= \sigma(\mathbf{X}t \mathbf{W}{xf} + \mathbf{H}{t-1} \mathbf{W}{hf} + \mathbf{b}f),\
\mathbf{O}t &= \sigma(\mathbf{X}t \mathbf{W}{xo} + \mathbf{H}{t-1} \mathbf{W}{ho} + \mathbf{b}_o),
\end{aligned}\end{split}
$$
- 隐状态H是一直传递下去,C的传递收到几个门控的影响。

图里面涉及记忆细胞更新的部分使用tanh,即输出在-1到1之间,而其他门控使用sigmoid控制在01之间
对应到代码里很直观
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,
W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)
F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)
O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o) # 这里的O和RNN中的O不同,是个门,RNN中的O直接是输出
C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c) # 候选记忆元
C = F * C + I * C_tilda # 记住多少
H = O * torch.tanh(C)
Y = (H @ W_hq) + b_q # 注意这里的输出就是把隐状态乘上Hq再加偏置
outputs.append(Y)
return torch.cat(outputs, dim=0), (H, C)实战:transformers库实现电影情感分析
目前打算跟pku的项目列表写一次PKU-TANGENT/nlp-tutorial: NLP新手入门教程 (github.com)
kaggle竞赛地址:Sentiment Analysis on Movie Reviews | Kaggle
这里发现一个很好的博客Jin blog (jinhanlei.github.io)讲了transformers和pytorch的配合使用
主体代码参考这段【精选】(六)使用Transformers进行情感分析_基于transformer的情感分析-CSDN博客
写的过程中遇到的问题
- 关于dataloder怎么移动到gpu上,其实是在训练代码中读入之后再移动到device
Pytorch 将Pytorch的Dataloader加载到GPU中|极客教程 (geek-docs.com)
- 用tqdm显示进度条
深度学习Pytorch通过tqdm实现进度条打印训练过程信息_pytorch训练进度条-CSDN博客
工作总结
- 基本上模型结构照搬博客里给的内容,输出层从单层的Linear改成了一个1024隐藏层的MLP。
- 博客中是输出0/1表示positive和negative,kaggle中的是一个5分类问题,我这里通过MLP输出到一个1*5的大小再通过softmax,把label变成onehot编码后计算损失。输出结果用argmax。
- 原文中使用了torchtext.data,但是这个包在0.9.0后被移除了,先处理好格式后再使用torch的dataloader也挺方便。
ELMo
- 在BiLSTM中,隐状态H是正向和反向两个LSTM的输出拼接。详解BiLSTM及代码实现 - 知乎 (zhihu.com)
- ELMo中embedding使用的是卷积的方法ELMo解读(论文 + PyTorch源码)_elmo代码-CSDN博客
- 这个比较好懂,而且解释的非常详细。ELMo原理解析及简单上手使用 - 知乎 (zhihu.com)
- ELMo大致了解就是一个多层的BiLM,对同一层中的正反LSTM进行concat连接,然后给每一层的输出加权相加得到最终输出。
$$
h_{k, j}^{L M}=\left[\overrightarrow{h_{k, j}^{L M}} ; \overleftarrow{h_{k, j}^{L M}}\right]
\
\mathbf{E L M o}k^{\text {task }}=E\left(R_k ; \Theta^{\text {task }}\right)=\gamma^{\text {task }} \sum{j=0}^L s_j^{\text {task }} \mathbf{h}_{k, j}^{L M}
$$
- RNN,LSTM的长程梯度消失问题,对于较长的句子,我们很难寄希望于将输入的序列转化为定长的向量而保存所有有效信息,即便 LSTM 加了门控机制可以选择性遗忘和记忆,随着所需翻译的句子难度怎能更加,这个结构的效果仍然不理想。
多头自注意力
- 关于多头注意力,看李沐的教学10.5. 多头注意力 — 动手学深度学习 2.0.0 documentation (d2l.ai)
- 沐神的代码:
#@save
class MultiHeadAttention(nn.Module):
"""多头注意力"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)- 使用GPT让他对forward函数的中间变量大小进行标注
B: batch_sizeTq: 查询的个数(queries)Tk: 键的个数(keys)Tv: 值的个数(values)H: 注意力头的个数(num_heads)D: 隐藏单元的个数(num_hiddens)
def forward(self, queries, keys, values, valid_lens):
# queries,keys,values的形状:
# (B,Tq,D), (B,Tk,D), (B,Tv,D)
# valid_lens的形状:
# (B,) 或 (B,Tq)
# 经过变换后,输出的queries,keys,values的形状:
# (B*H,Tq,D/H), (B*H,Tk,D/H), (B*H,Tv,D/H)
queries = transpose_qkv(self.W_q(queries), self.num_heads) # (B*H, Tq, D/H)
keys = transpose_qkv(self.W_k(keys), self.num_heads) # (B*H, Tk, D/H)
values = transpose_qkv(self.W_v(values), self.num_heads) # (B*H, Tv, D/H)
if valid_lens is not None:
# 在轴0,将第一项(标量或者矢量)复制H次,
# 然后如此复制第二项,然后诸如此类。
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0) # (B*H,)
# output的形状: (B*H, Tq, D/H)
output = self.attention(queries, keys, values, valid_lens)
# output_concat的形状: (B, Tq, D)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat) # (B, Tq, D)
- 其实代码很难懂,但是评论区有人画了一张图来表示中间shape的变化,非常形象
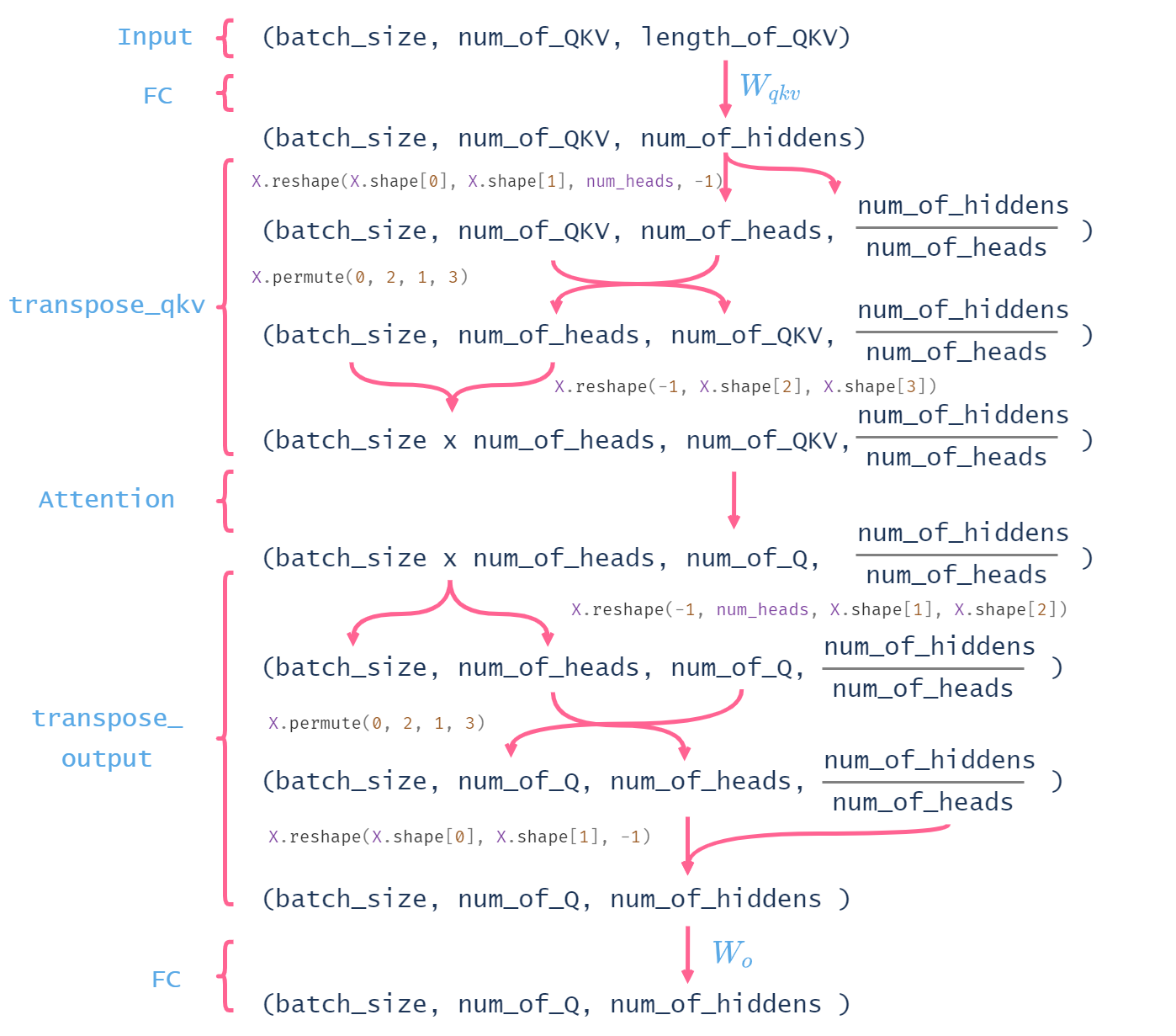
BERT
- 代码依旧是看李沐d2l的代码14.8. 来自Transformers的双向编码器表示(BERT) — 动手学深度学习 2.0.0 documentation (d2l.ai)
- 这篇相对详细 读懂BERT,看这一篇就够了 - 知乎 (zhihu.com)
def get_tokens_and_segments(tokens_a, tokens_b=None):
"""获取输入序列的词元及其片段索引"""
tokens = ['<cls>'] + tokens_a + ['<sep>']
# 0和1分别标记片段A和B
segments = [0] * (len(tokens_a) + 2) # A句的分割嵌入为0
if tokens_b is not None:
tokens += tokens_b + ['<sep>']
segments += [1] * (len(tokens_b) + 1) # B句的设置为1
return tokens, segments三种embedding
- bert的输入是句子的三层表征:token,分割(a句/b句),位置。对应到代码中的token_embedding,segement_embedding和pos_embedding(是learnable的参数)
class BERTEncoder(nn.Module):
"""BERT编码器"""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
**kwargs):
super(BERTEncoder, self).__init__(**kwargs)
self.token_embedding = nn.Embedding(vocab_size, num_hiddens)
self.segment_embedding = nn.Embedding(2, num_hiddens)
self.blks = nn.Sequential() # 串联encoder block
for i in range(num_layers):
self.blks.add_module(f"{i}", d2l.EncoderBlock(
key_size, query_size, value_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, dropout, True))
# 在BERT中,位置嵌入是可学习的,因此我们创建一个足够长的位置嵌入参数
self.pos_embedding = nn.Parameter(torch.randn(1, max_len,
num_hiddens))
def forward(self, tokens, segments, valid_lens):
# 在以下代码段中,X的形状保持不变:(批量大小,最大序列长度,num_hiddens)
X = self.token_embedding(tokens) + self.segment_embedding(segments)
X = X + self.pos_embedding.data[:, :X.shape[1], :] # 加入位置编码
for blk in self.blks:
X = blk(X, valid_lens)
return X- 从代码中也可以看出,bert的embedding是三种embedding的直接求和
- 因为NLP没有CV的Imagenet这样庞大数据集,所以bert主要还是采用无监督学习的方式。两个任务:Masked Language Model(随机添加mask/替换句子)和Next Sentence Prediction(预测两个句子是不是连在一起)
class MaskLM(nn.Module):
"""BERT的掩蔽语言模型任务"""
def __init__(self, vocab_size, num_hiddens, num_inputs=768, **kwargs):
super(MaskLM, self).__init__(**kwargs)
self.mlp = nn.Sequential(nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.LayerNorm(num_hiddens),
nn.Linear(num_hiddens, vocab_size))
def forward(self, X, pred_positions):
num_pred_positions = pred_positions.shape[1]
pred_positions = pred_positions.reshape(-1) # 输入是2维的所以reshape一下
batch_size = X.shape[0]
batch_idx = torch.arange(0, batch_size)
batch_idx = torch.repeat_interleave(batch_idx, num_pred_positions) # 将batch_idx中的每个元素重复num_pred_positions次
# 假设batch_size=2,num_pred_positions=3
# 那么batch_idx是np.array([0,0,0,1,1,1])
masked_X = X[batch_idx, pred_positions]
# 在每个batch中找到对应被掩盖的位置的输出,单独拎出来
masked_X = masked_X.reshape((batch_size, num_pred_positions, -1))
# masked_X shape: [batch_size, sequence_length, feature_dim]
# 一开始有疑问为什么没有用mask替换的代码
# 因为已经在数据预处理阶段被替换为掩盖标记
mlm_Y_hat = self.mlp(masked_X) # 经过一个MLP得到预测
return mlm_Y_hat
mlm = MaskLM(vocab_size, num_hiddens)
mlm_positions = torch.tensor([[1, 5, 2], [6, 1, 5]]) # batchsize = 2
mlm_Y_hat = mlm(encoded_X, mlm_positions)
# 计算损失
mlm_Y = torch.tensor([[7, 8, 9], [10, 20, 30]])
loss = nn.CrossEntropyLoss(reduction='none')
mlm_l = loss(mlm_Y_hat.reshape((-1, vocab_size)), mlm_Y.reshape(-1))- 上面很多理解都写到注释里面去了
我的疑问
- 问:那这些被mask的位置之间可能相隔很远没有关联,每组不同的输入他们的位置关系也会变化,为什么要传入同一个MLP中呢?
GPT:
- 您提出的观点是正确的:在掩蔽语言模型(Masked Language Model, MLM)任务中,被掩盖的位置可能在输入文本中相隔很远,它们之间可能没有直接的关联。此外,不同的输入示例可能具有不同的掩盖位置,因此这些位置之间的关系会变化。
- MLP模型的目标是理解上下文并预测掩盖位置上的单词。尽管这些位置之间可能没有直接的关联,但上下文中的其他单词提供了相关信息,帮助模型进行预测。共享的MLP可以捕获这些上下文信息。- 感觉这个回答还是有点玄学的,不过从代码来看,确实是直接把pred_position位置的特征单独拿出来,不管他们在句中的位置间隔是否固定,直接一起传到MLP里面去。
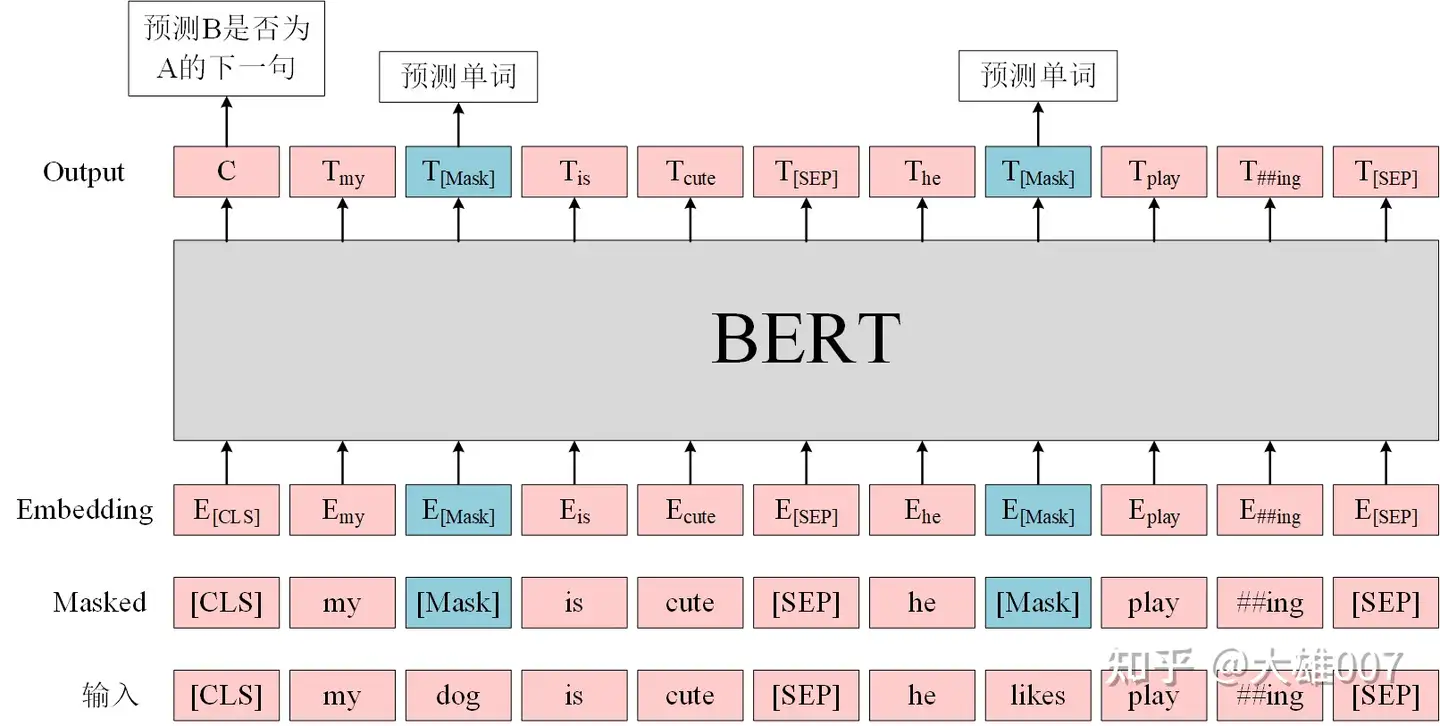
这里也解释了为什么引入CLS token:对于一些token级别的任务(如,序列标注和问答任务),就把Ti输入到额外的输出层中进行预测。对于一些句子级别的任务(如,自然语言推断和情感分类任务),就把C输入到额外的输出层中,这里也就解释了为什么要在每一个token序列前都要插入特定的分类token。
关于elmo,bert,GPT1的区别
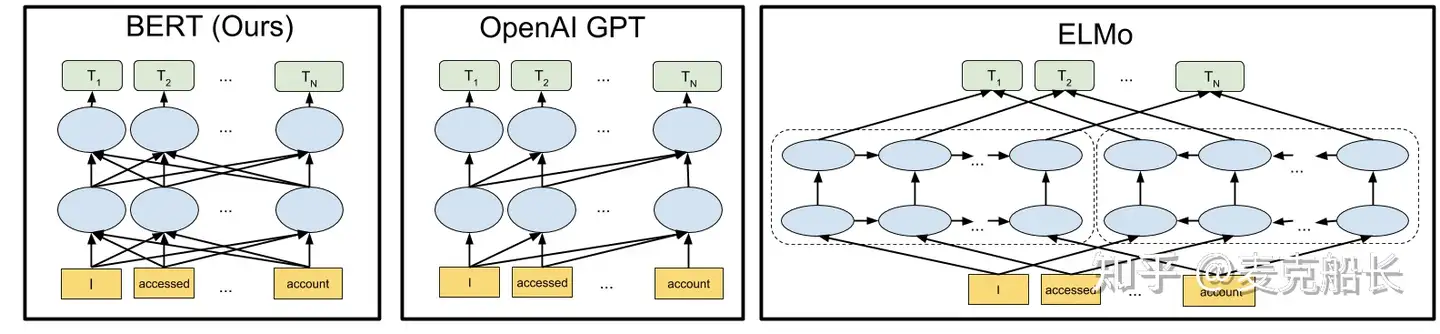
Huggingface Transformers
- 在transformers库源代码目录下src/transformers/下有各种主要功能的代码,比如/src/transformers/models/bert/modeling_bert.py中的bert源码
- 这个是transformers库文件结构的介绍视频,里面一整个系列都是带读transformers库源码的,之后有时间再看。https://www.bilibili.com/video/BV1Tm4y1M7nQ
- 关于transformers库如何配合pytorch使用Transformers快速入门(四):结合Transformers和PyTorch修改模型 | Jin blog (jinhanlei.github.io)
Transformers库BLIP2代码阅读
视觉embedding部分
- 通过一个ViT,把不同分辨率的图片映射
class Blip2VisionEmbeddings(nn.Module):
def __init__(self, config: Blip2VisionConfig):
super().__init__()
self.config = config
self.embed_dim = config.hidden_size
self.image_size = config.image_size
self.patch_size = config.patch_size
self.class_embedding = nn.Parameter(torch.randn(1, 1, self.embed_dim))
# CLS token,是可学习的
self.patch_embedding = nn.Conv2d(
in_channels=3, out_channels=self.embed_dim, kernel_size=self.patch_size, stride=self.patch_size
) # 注意这里stride == patch_size,说明是每个patch和卷积核卷积提取特征
# 从3个通道到embed_dim个通道,是为了映射到和单词同样的维度。这里
self.num_patches = (self.image_size // self.patch_size) ** 2 # 适用于不同分辨率的图片,图片变大则patch变多
self.num_positions = self.num_patches + 1
self.position_embedding = nn.Parameter(torch.randn(1, self.num_positions, self.embed_dim)) # 使用可学习的位置编码
def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
batch_size = pixel_values.shape[0]
target_dtype = self.patch_embedding.weight.dtype
patch_embeds = self.patch_embedding(pixel_values.to(dtype=target_dtype)) # shape = [*, width, grid, grid]
# 通过卷积,分patch
patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
class_embeds = self.class_embedding.expand(batch_size, 1, -1).to(target_dtype)
embeddings = torch.cat([class_embeds, patch_embeds], dim=1) # 把CLS token和图片embedding 接在一起
embeddings = embeddings + self.position_embedding[:, : embeddings.size(1), :].to(target_dtype) # 加上位置编码
return embeddingsAttention
class Blip2Attention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(self, config):
super().__init__()
self.config = config
self.embed_dim = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.embed_dim // self.num_heads
if self.head_dim * self.num_heads != self.embed_dim:
raise ValueError(
f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
f" {self.num_heads})."
)
self.scale = self.head_dim**-0.5
self.dropout = nn.Dropout(config.attention_dropout)
# small tweak here compared to CLIP, no bias here
self.qkv = nn.Linear(self.embed_dim, 3 * self.embed_dim, bias=False)
# 不单独建Wq,Wk,Wv,直接和在一起和input相乘,所以是3*embed_dim
# 如果是单独一个q,就是q = nn.Linear(self.embed_dim, self.embed_dim, bias=False)
if config.qkv_bias:
q_bias = nn.Parameter(torch.zeros(self.embed_dim)) # 参数设置是否使用bias
v_bias = nn.Parameter(torch.zeros(self.embed_dim))
else:
q_bias = None
v_bias = None
if q_bias is not None:
qkv_bias = torch.cat((q_bias, torch.zeros_like(v_bias, requires_grad=False), v_bias))
self.qkv.bias = nn.Parameter(qkv_bias)
self.projection = nn.Linear(self.embed_dim, self.embed_dim)
# 模态投影层projection layer
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
def forward(
self,
hidden_states: torch.Tensor,
head_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
"""Input shape: Batch x Time x Channel"""
bsz, tgt_len, embed_dim = hidden_states.size()
mixed_qkv = self.qkv(hidden_states) # 这里为了方便计算,不单独建Wq,Wk,Wv,直接和在一起和input相乘
mixed_qkv = mixed_qkv.reshape(bsz, tgt_len, 3, self.num_heads, embed_dim // self.num_heads).permute(
2, 0, 3, 1, 4
) # 把维度重排,原本2维度上拼接起来的qkv结果,这里给他移动到第0维,方便后面拆分
# 这里的5个维度:qkv拼接,batch大小,注意力头数,序列长度,embed_dim
query_states, key_states, value_states = mixed_qkv[0], mixed_qkv[1], mixed_qkv[2]
# 在第0维上拆分成q k v
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_states, key_states.transpose(-1, -2))
# 相当于q(seq_len, embed_dim) * k(embed_dim, seq_len) 相乘
attention_scores = attention_scores * self.scale
# 缩放操作是为了确保在计算 softmax 函数时,分数不会因为维度的不同而导致数值问题
# Normalize the attention scores to probabilities.
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
# 通过softmax计算得到attention_probs
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# 这里介绍了attention进行dropout的方式,直接对attention_prob进行dropout,而不是计算后再对结果dropout
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_states).permute(0, 2, 1, 3)
new_context_layer_shape = context_layer.size()[:-2] + (self.embed_dim,)
context_layer = context_layer.reshape(new_context_layer_shape)
output = self.projection(context_layer)
# 经过projection layer输出结果
outputs = (output, attention_probs) if output_attentions else (output, None)
return outputs- 值得注意的是里面把WqWkWv相接到同一个Linear中,输入经过线性层后再拆分出qkv。
- 而且在attention中的dropout,直接对attention_prob进行dropout,而不是计算后再对结果dropout
阅读LLM综述
人工智能 LLM 革命破晓:一文读懂当下超大语言模型发展现状 /麦克船长LLM革命系列2 - 知乎 (zhihu.com)
- 之前一直不理解为什么叫few-shot prompt:在无监督训练好的 GPT-3,使用时用少量示例(加在prompt里面)就可以得到有较好的输出反馈,这就叫 Few-Shot Prompt。pretrain后的模型通过finetune或者In-context learning完成不同类型的任务,又分zeroshot,oneshot,fewshot,在综述的11.5节有详细区分。
topk,topp和tempreture
topk即从前k个高概率的token中随机选,topp是从概率和为topp的前几个token中随机,而tempreture是在softmax中除上了一个系数T,来控制模型的随机性,T越大生成的内容越随机
RoPE编码
- 参考1超超超超超简单!从结果推导RoPE旋转位置编码 - 知乎 (zhihu.com)
- 参考2【论文阅读】RoPE为何成为大模型中最常见的位置编码? - 知乎 (zhihu.com)
- $\langle f(q, m), f(k, n) \rangle = g(q, k, m - n)$怎么理解?
- f(q,m)和f(k,n)表示查询qk的位置编码,做内积之后,要和g(q, k, m-n)算出来的相等,即结果是和相对位置m-n相关的,要找这样一个映射(位置编码方式)f。
- 一开始的疑问是,为什么$e^{m\theta i}$和$e^{n\theta i}$乘积不是$e^{(m+n)\theta i}$而是$e^{(m-n)\theta i}$,因为两个复向量q,k的内积等于q乘(k的共轭复数),再取实部即$\langle q,k\rangle = Re(q^*k)$。复数内积参考复向量的内积(例题详解)-CSDN博客

共轭复数的定义是将复数的虚部取负值,对于复数 $re^{\theta i}$,其共轭复数为$re^{-\theta i}$。
感觉论文中的2D的例子,可以发现



