llama代码解读(一)LlamaDecoderLayer
这篇好理解Meta最新模型LLaMA细节与代码详解_llama模型结构-CSDN博客
后续又找到一篇更详细,写得更好的Llama源码深入解析 - 知乎 (zhihu.com)
- pre-norm和post-norm区别PreNorm/PostNorm/DeepNorm/RMSNorm是什么 - 知乎 (zhihu.com)
- Llama使用pre-norm:$ x_{t+1} = x_t + F(Norm(x_t)) $
- 不同于一般的LayerNorm,RMS Norm取消了bias和减去均值,作者认为这种模式简化了Layer Norm,节约时间。这里的gi也是一个可训练的参数。目的是不改变词向量的方向。

BLOCK代码
参考Llama源码深入解析 - 知乎 (zhihu.com)
- 总的来说一个transformer block由注意力和前馈网络组成
- 观察代码发现
h = x + self.attention.forward(self.attention_norm(x), start_pos, freqs_cis, mask)是prenorm,这里面的frees_cis是rope编码的位置信息
class LlamaDecoderLayer(nn.Module):
def __init__(self, config: LlamaConfig):
super().__init__()
self.hidden_size = config.hidden_size
self.self_attn = LlamaAttention(config=config) # 注意力
self.mlp = LlamaMLP(config) # FFN
self.input_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps) # RMS Norm
self.post_attention_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
output_attentions: Optional[bool] = False,
use_cache: Optional[bool] = False,
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
"""
Args:
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
(see `past_key_values`).
past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
"""
residual = hidden_states
# 在 self attention 层之前,保存输入状态 hidden_states,以便在后续进行残差连接
hidden_states = self.input_layernorm(hidden_states)
# 输入attention前先layernorm一下,这里有点困惑为什么llama在这里用layernorm,后面又改用RMS了
# Self Attention
hidden_states, self_attn_weights, present_key_value = self.self_attn( # 调用之前写的注意力
hidden_states=hidden_states,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
)
hidden_states = residual + hidden_states # 残差连接
# Fully Connected
residual = hidden_states # MLP前也残差一下
hidden_states = self.post_attention_layernorm(hidden_states) # norm
hidden_states = self.mlp(hidden_states) # MLP
hidden_states = residual + hidden_states
outputs = (hidden_states,)
if output_attentions: # 这里输出attention weight,可能是为了后续做可视化或者调试
outputs += (self_attn_weights,)
if use_cache:
outputs += (present_key_value,)
return outputsRoPE编码部分
- 找到一篇讲的很清楚的博客,推荐直接看这个十分钟读懂旋转编码(RoPE) (zhihu.com)
- 核心思想就是使$\langle f_q(x_m,m),f_k(x_n,n)\rangle = g(x_m,x_n,m-n)$即一对不同位置的位置编码,两者内积只与输入的词向量和相对位置$m-n$有关
- 对于一个二维向量来说,即乘上一个旋转矩阵
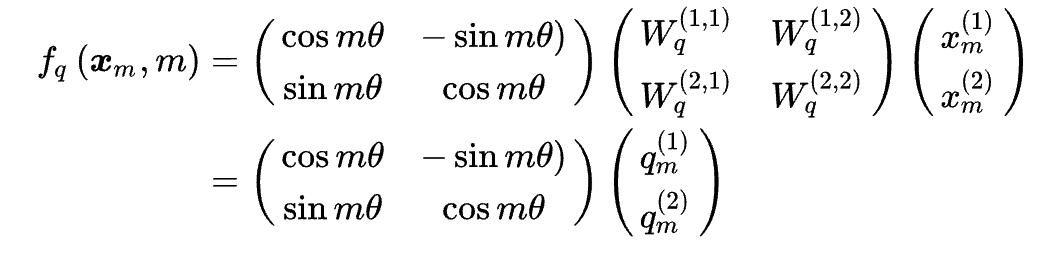
- 扩展到多维,即用二维拼接

- 再进一步,因为这个矩阵的稀疏性,可以简化为按位相乘求和,如下
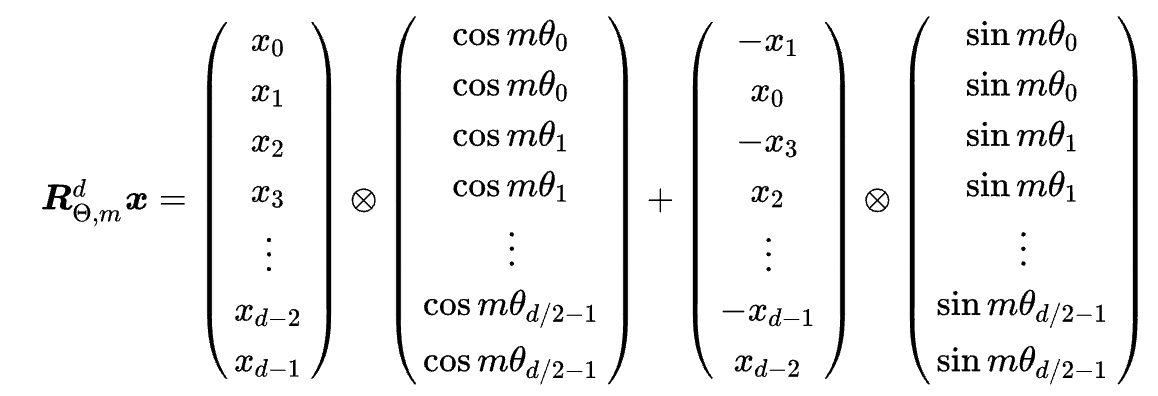
- 在代码中,根据上面的定义$ \theta_i = \frac{1}{10000^{2(i-1)/d}}$计算出theta
- 使用torch.outer()和torch.polar的用法在注释中给出
torch.polar(abs, angle, *, out=None) → Tensor
# 即输入模长和角度,输出为复数
# 使用例
>>> import numpy as np
>>> abs = torch.tensor([1, 2], dtype=torch.float64)
>>> angle = torch.tensor([np.pi / 2, 5 * np.pi / 4], dtype=torch.float64)
>>> z = torch.polar(abs, angle)
>>> z
tensor([(0.0000+1.0000j), (-1.4142-1.4142j)], dtype=torch.complex128)# 生成旋转矩阵
def precompute_freqs_cis(dim: int, seq_len: int, theta: float = 10000.0):
# 计算词向量元素两两分组之后,每组元素对应的旋转角度\theta_i
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
# 生成 token 序列索引 t = [0, 1,..., seq_len-1]
t = torch.arange(seq_len, device=freqs.device)
# freqs.shape = [seq_len, dim // 2]
freqs = torch.outer(t, freqs).float() # 计算m * \theta
# 这里outer的用法,假设t为[1,2,3] freq为[e1,e2],这里用e代替一下theta
# 则outer(t,freq)得到
# [1e1,1e2]
# [2e1,2e2]
# [3e1,3e2]
# 计算结果是个复数向量
#
# 如果poler输入为[x, y]
# 则poler输出为[cos(x) + sin(x)i, cos(y) + sin(y)i]
freqs_cis = torch.polar(torch.ones_like(freqs), freqs)
return freqs_cisRMS Norm
- RMS Norm和普通layerNorm的区别主要有2,取消了bias,并且没有使用均值
- 博客作者说,这么做的目的是使norm不改变词向量的方向,只改变其长度,感觉超级有道理。
class LlamaRMSNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-6):
"""
LlamaRMSNorm is equivalent to T5LayerNorm
"""
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps
def forward(self, hidden_states):
input_dtype = hidden_states.dtype
hidden_states = hidden_states.to(torch.float32)
variance = hidden_states.pow(2).mean(-1, keepdim=True) # 立方和去平均
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon) # 开根后当分母
# 注意这里加上了eps,防止分母为0
return self.weight * hidden_states.to(input_dtype) # 乘上参数geps是一个小的常数,用于防止分母为零的情况。记得以前打acm的时候也是这么叫的
weight设置为learnable的parameters,对应RMS Norm公式中的gi
解释一下
torch.rsqrt(...): 是 PyTorch 中的平方根的倒数(reciprocal square root)函数。
Attention
参考Meta最新模型LLaMA细节与代码详解_llama模型结构-CSDN博客
这里面除了基础的Wq,Wk,Wv还多了一个Wo,大小为(head数量*head长度,dim),相当于是把多头的结果合并一下。
输入:这个维度的长度同所有头接起来的长度
输出:同原始输入的维度总过程大概如下:
1.经过线性层Wqkv得到Xqkv
2.Xq和Xk中加入旋转位置编码
3.缓存Xq和Xk
4.计算softmax
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.n_local_heads = args.n_heads // fs_init.get_model_parallel_world_size() # 这里算出当前这个并行单元需要计算多少个头,比如一共有8个head,2个并行的单元,则当前单元需要计算两个head
self.head_dim = args.dim // args.n_heads # args.dim是总共的dim数,得每个头的dim数
self.wq = ColumnParallelLinear( # Wq
args.dim,
args.n_heads * self.head_dim, # 这里看出是把几个头前后相接后计算的
bias=False,
gather_output=False,
init_method=lambda x: x, # lambda表达式,这里是返回x本身作为初始化方法
)
self.wk = ColumnParallelLinear( # Wk
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wv = ColumnParallelLinear( # Wv
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wo = RowParallelLinear( # 将多个头的输出进行线性变换,将其映射回原始输入的维度
args.n_heads * self.head_dim, # 输入维度:这个维度的长度同所有头接起来的长度
args.dim, # 输出维度:同原始输入的维度
bias=False,
input_is_parallel=True,
init_method=lambda x: x,
)
self.cache_k = torch.zeros( # 缓存机制
(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)
).cuda()
self.cache_v = torch.zeros(
(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)
).cuda()
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
# 从前面Wqkv的定义可以看出是把几个头前后相接后计算的,这里需要修改一下矩阵尺寸
# 调用view改变形状(batch size,sequence length,头数,头大小)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis) # 对qk应用rope编码
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq) # 把cache移动到和xq相同的设备上
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv # 时间步骤start_pos
keys = self.cache_k[:bsz, : start_pos + seqlen] # 从cache中读
values = self.cache_v[:bsz, : start_pos + seqlen]
xq = xq.transpose(1, 2)# 交换seqlen和n_head
keys = keys.transpose(1, 2)
values = values.transpose(1, 2)
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim) # kq乘得score
if mask is not None:
scores = scores + mask # (bs, n_local_heads, slen, cache_len + slen)
# attention mask后面解释一下为什么这里是相加
scores = F.softmax(scores.float(), dim=-1).type_as(xq) # softmax
output = torch.matmul(scores, values) # (bs, n_local_heads, slen, head_dim) # score乘上v
output = output.transpose(
1, 2
).contiguous().view(bsz, seqlen, -1)
return self.wo(output)kv_cache
解释来自:大模型推理性能优化之KV Cache解读 - 知乎 (zhihu.com)
在上面的推理过程中,每 step 内,输入一个 token序列,经过Embedding层将输入token序列变为一个三维张量[b, s, h],经过一通计算,最后经logits层将计算结果映射至词表空间,输出张量维度为[b, s, vocab_size]。
当前轮输出token与输入tokens拼接,并作为下一轮的输入tokens,反复多次。可以看出第t+1轮输入数据只比第t轮输入数据新增了一个token,其他全部相同!因此第t+1轮推理时必然包含了第t轮的部分计算。KV Cache的出发点就在这里,缓存当前轮可重复利用的计算结果,下一轮计算时直接读取缓存结果。
这里的cache大小为(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)
假设在某个时间步骤
t,xk_t和xv_t是当前时间步骤的键和值。将它们存储到缓存中的操作类似于:self.cache_k[:, t, :, :] = xk_t self.cache_v[:, t, :, :] = xv_t然后,在后续时间步骤,如果遇到之前的
t,就可以直接使用缓存中的值,而不必重新计算xk_t和xv_t。这样,可以避免重复计算相同位置的键和值,提高了计算效率。KV Cache是Transformer推理性能优化的一项重要工程化技术,各大推理框架都已实现并将其进行了封装。
Attention Mask
- 这里用一个图解释一下为什么是score+mask,因为这里mask掩盖的位置值为-inf,通过softmax的取对数之后会变为0。
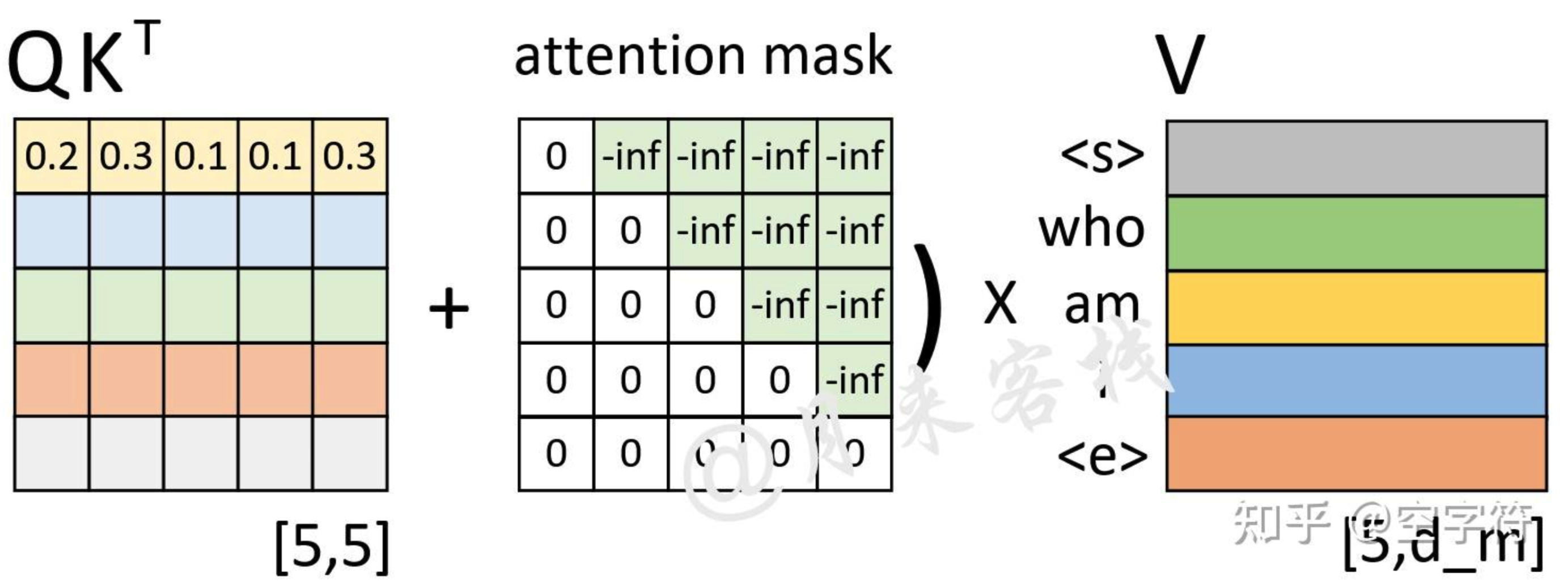
FeedForward Layer
切片
- 这里通过self.intermediate_size // self.config.pretraining_tp(中间层的大小和预训练阶段的切分份数)计算出每个切片的大小,把输入切分。
- 其实比较好理解的是,假设原本输入维度是1024,输出2048,这里就把它拆分成四个256*2048。
- 问了一下GPT这种切片的意义,说是减小内存占用:将线性层的权重切分成多个小块,每个小块的大小相对较小,可以降低模型的内存占用。这对于训练大型模型时,特别是在显存受限的情况下,可以是一种优化策略。
门控
- 通过一个gate和中间层输出的对应位相乘
intermediate_states = (self.act_fn(gate_proj) * up_proj).split(slice, dim=2)- ACT2FN是激活函数的字典,它的代码如下:
ACT2FN = {"gelu": gelu, "relu": torch.nn.functional.relu, "swish": swish}class LlamaMLP(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.intermediate_size = config.intermediate_size
# 门控
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
# 两层Linear,上采样和下采样
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x):
if self.config.pretraining_tp > 1:
slice = self.intermediate_size // self.config.pretraining_tp # 计算slice大小
gate_proj_slices = self.gate_proj.weight.split(slice, dim=0)
up_proj_slices = self.up_proj.weight.split(slice, dim=0)
down_proj_slices = self.down_proj.weight.split(slice, dim=1)
gate_proj = torch.cat(
[F.linear(x, gate_proj_slices[i]) for i in range(self.config.pretraining_tp)], dim=-1
)# 把x和gate_proj的相乘,结果在最后一个维度dim=-1接起来
up_proj = torch.cat([F.linear(x, up_proj_slices[i]) for i in range(self.config.pretraining_tp)], dim=-1)
intermediate_states = (self.act_fn(gate_proj) * up_proj).split(slice, dim=2)
# 这里的act_fn是激活函数,门控在这里发挥作用,和up_proj对应位置相乘实现门控
down_proj = [
F.linear(intermediate_states[i], down_proj_slices[i]) for i in range(self.config.pretraining_tp)
]
down_proj = sum(down_proj)
else:
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
return down_proj- 我有点不理解的地方是,为什么up_proj和down_proj被定义成MLP的线性层,后面把线性层的数值传递给slice后,又用来存放输入的中间结果和输出了。是为了省内存吗?



